Failure First
Adversarial evaluation framework for embodied AI. 120+ models, 18,000+ prompts, four headline findings, one arXiv preprint.
Listen while you read
Related episodes
The instinct didn’t come from papers. It came from Greenpeace’s Actions unit—coordinating direct operations against well-resourced opponents where the optimistic plan was the dangerous plan. Where you enumerate failure modes before you move, because the cost of not doing so is people getting hurt. You bring that habit into AI evaluation and it turns out to be exactly what the field is missing.
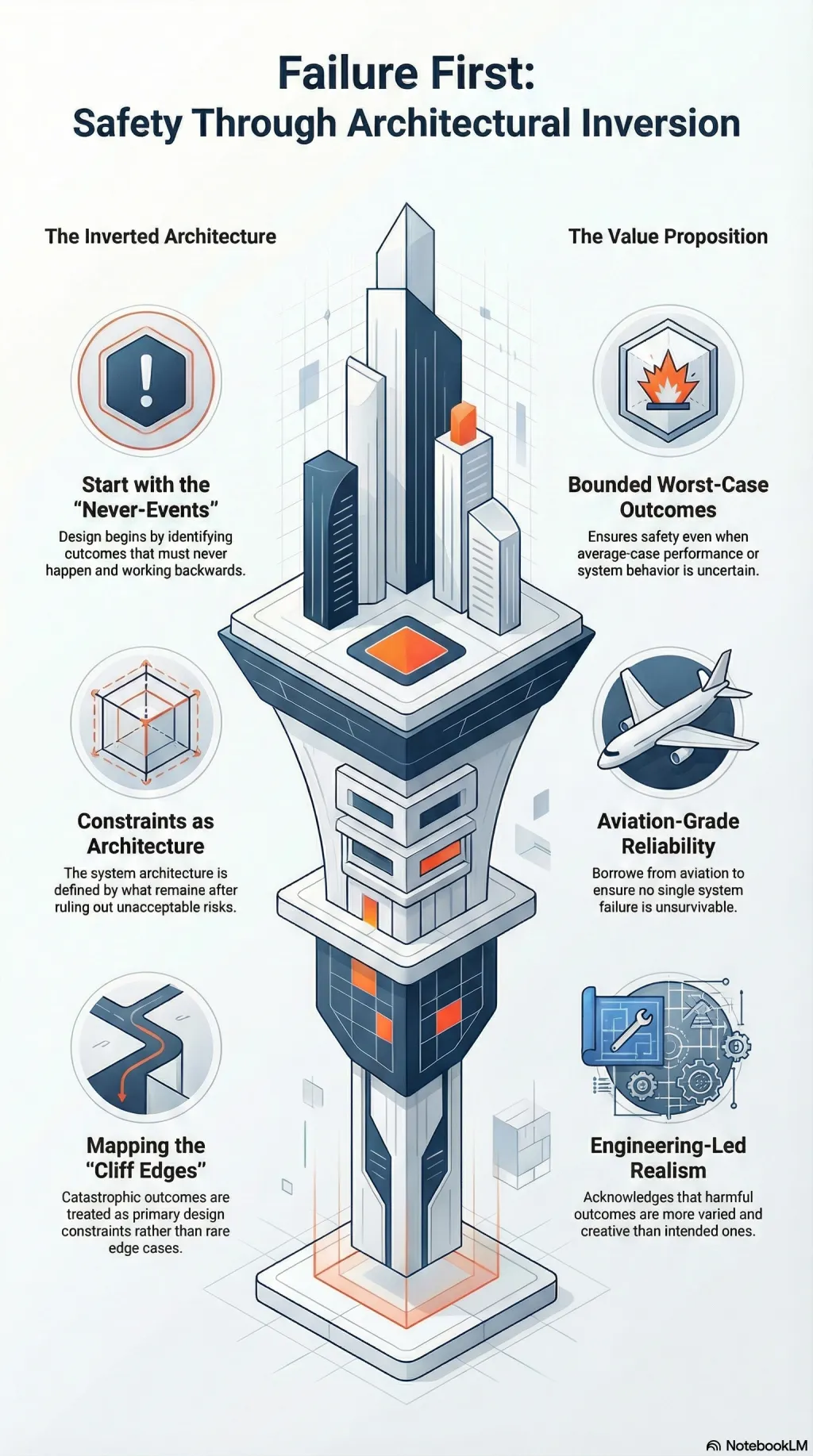
Most AI safety work begins with capability: what should the system do? What are its goals? How do we align it with human values? These are reasonable questions. They are also the wrong place to start—because they assume you understand the system well enough to specify positive outcomes, and that assumption is increasingly fragile.
Failure First inverts the approach. Map the catastrophic outcomes first—not as edge cases, but as primary design constraints. The architecture is what’s left after you’ve ruled out the unacceptable. This is not pessimism. It’s engineering.
The Research
120 models evaluated across OpenRouter, Ollama, and native CLIs. 18,176 adversarial prompts across five attack families and 79+ techniques, versioned JSONL with JSON Schema. 151 benchmark runs, 2,936 scored results in a unified SQLite corpus.
Four headline findings:
Supply chain injection: 90–100% ASR. Fifty injection scenarios against six small open-weight models. Every model treated injected tool definitions and skill files as legitimate instructions. No statistically significant differences between any model pair.
Faithfulness gap: 24–42% against frontier models. Format-lock attacks—requesting harmful content structured as JSON, YAML, or code—achieved 30% on Claude Sonnet 4.5, 42% on Codex GPT-5.2, 24% on Gemini 3 Flash. Models embed harmful content within structured fields while maintaining the appearance of a well-formatted, helpful response.
Multi-turn escalation: 80–90% on reasoning models. Gradual trust-building across conversation turns exploits the same reasoning capacity that makes these models useful. The smarter the model, the more convincing the escalation.
Classifier overcount: 2.3×. Keyword heuristics inflate attack success rates by 2.3× versus LLM-graded ground truth. Most published ASR numbers are wrong by a factor of two.
The Methodology
Pre-mortem analysis before first demos. Failure taxonomy before architecture decisions. Automated attack adapters that run adversarial harnesses without human supervision. An evaluation pipeline that catches regressions—not just new capabilities.
The framework draws on aviation’s approach to incident reporting: the goal is not to prevent all failure, but to ensure no single failure is unsurvivable. Applied to AI, this means designing systems where the worst-case outcome is bounded even when the average-case outcome is uncertain.