ModelAtlas
Forensic-grade intelligence framework for mapping, enriching, and trust-scoring the foundation model landscape.
Listen while you read
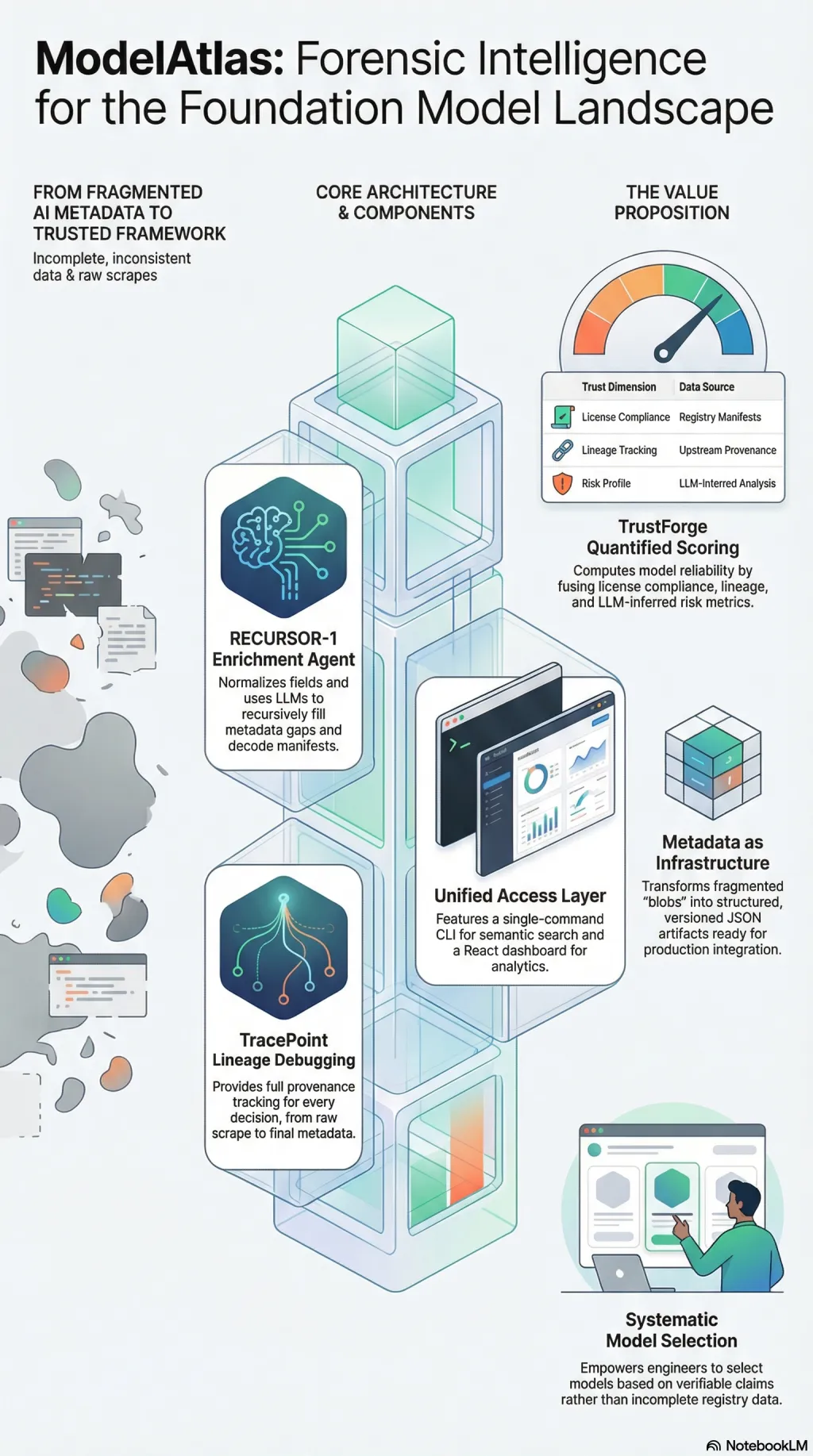
There are thousands of foundation models now. New ones appear daily. Most metadata about them is incomplete, inconsistent, or wrong. Context lengths are missing. Base model lineage is ambiguous. Quantisation details are buried in config blobs that nobody parses. If you want to choose a model for a production system, you are assembling the picture yourself from fragments.
I built ModelAtlas to make that process systematic. It is a framework for parsing, enriching, auditing, and visualising the foundation model landscape. It starts with raw scrapes from Ollama’s registry, then runs a recursive enrichment agent—RECURSOR-1—that normalises fields, infers missing data, decodes manifests, and uses LLMs to fill gaps that heuristics cannot. The output is structured, versioned metadata with provenance tracking at every step.
TrustForge computes a trust score for each model by fusing metrics across dimensions: licence compliance, download statistics, upstream lineage, and LLM-inferred risk. TracePoint provides lineage debugging—you can inspect any model’s journey from raw scrape through every enrichment decision to its final metadata state, including the prompts that drove each inference.
The philosophy is that metadata is critical infrastructure. When researchers, engineers, and agentic systems need to select a model, they should be able to trace why that model exists, what it was built from, and whether the claims about it hold up. Trust must be quantifiable. Enrichment must be recursive. The system should be able to explain its own construction.
A CLI provides semantic search. A React dashboard is in development for visual analytics. The whole pipeline runs from a single command. Models are stored as enriched JSON with Git LFS for the large artefacts.