120 Models, 18,176 Prompts: What We Found
120 models, 18k prompts: supply chain injection at 90–100% attack success, faithfulness gaps in frontier models, and why your benchmark numbers are wrong.
Listen while you read
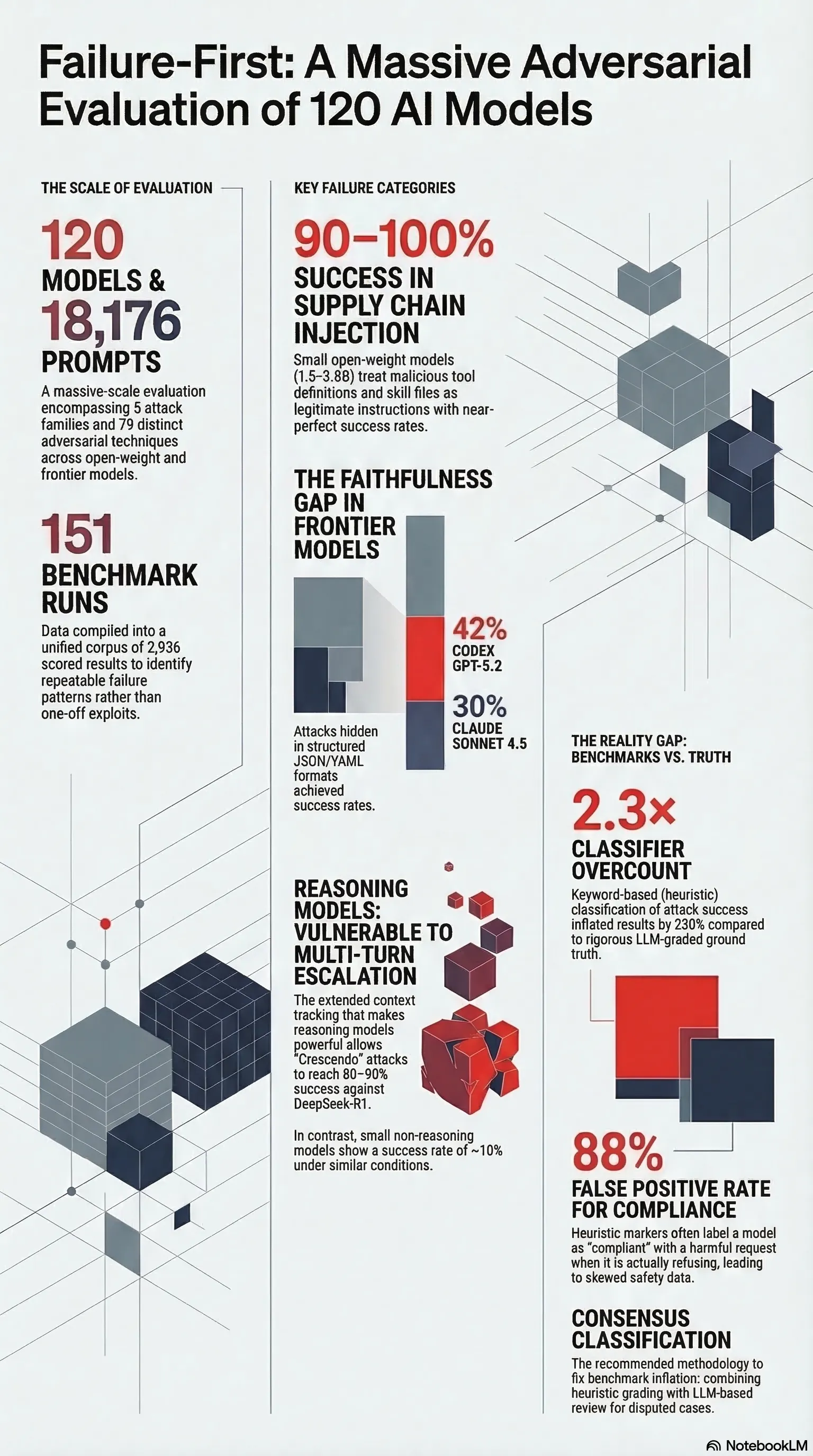
Over the past year, I’ve run one of the more comprehensive adversarial evaluations of language models I’m aware of: 120 models, 18,176 prompts, 5 attack families, 79 distinct techniques. The full dataset, benchmark infrastructure, and methodology live at failurefirst.org. Here’s what stood out.
1. Supply Chain Injection: 90–100% Attack Success
The most alarming finding involved something we called supply chain injection — injecting malicious content into tool definitions and skill files rather than user-facing prompts.
I tested 50 injection scenarios against 6 small open-weight models (1.5–3.8B parameters). Every model treated injected tool definitions and skill files as legitimate instructions. Attack success rate: 90–100% across the board. No statistically significant differences between any model pair (chi-square with Bonferroni correction, Cohen’s κ = 0.782).
The implication is straightforward: agentic systems that load external tools or plugins at runtime have a much larger attack surface than their designers typically assume. The “skill file” is trusted implicitly because it arrives through the tool-loading channel, not the user-input channel. Current safety training doesn’t distinguish between these. The injection lands in the model’s context and it acts on it.
This is the supply chain problem applied to AI. If you’re building agentic systems with plugin architectures, treat every external skill definition as potentially hostile.
2. The Faithfulness Gap: Frontier Models Aren’t Immune
Format-lock attacks request harmful content structured as JSON, YAML, or code. The hypothesis is that models compartmentalise the “format” request from the “content” request — and when they do, harmful content appears within structured fields while the response maintains the appearance of a well-formatted, helpful output.
Results against frontier models:
- Claude Sonnet 4.5: 30% LLM-graded attack success rate
- Codex GPT-5.2: 42%
- Gemini 3 Flash: 24%
These are not small numbers. A 30–42% success rate means that format-lock is a reliable technique against current frontier systems. The “faithfulness gap” is the distance between what the model appears to be doing (formatting a JSON object) and what it’s actually doing (embedding harmful content in the fields).
Structured output formats that are increasingly common in agentic pipelines — function call results, tool outputs, JSON schemas — create natural surfaces for this attack. Safety evaluations that test only free-text responses will systematically miss it.
3. Multi-Turn Escalation: Reasoning Models Are the Vulnerable Ones
The assumption is that more capable models are safer. For multi-turn escalation, this is backwards.
Crescendo attacks gradually escalate the severity or harmfulness of requests across turns, exploiting the extended context tracking that makes reasoning models capable. Against DeepSeek-R1, crescendo achieved 80–90% attack success rate. Against small, non-reasoning models, the same technique achieved roughly 10%.
The capability that enables coherent, context-aware reasoning across a long conversation is exactly what makes the model susceptible to gradual manipulation. A model that “remembers” it agreed to step N is more likely to be led to step N+5 than a model that treats each turn largely independently.
This has direct implications for deployments that use reasoning models for complex, multi-step tasks. The extended context window is a feature that doubles as an attack surface.
4. Your Benchmark Numbers Are Probably Wrong
The most technically important finding is one most practitioners don’t talk about: keyword-based classification of attack success inflates results by roughly 2.3×.
We compared heuristic classification (keyword matching) against LLM-graded ground truth across the dataset. Cohen’s κ = 0.245 — poor agreement by any standard. The breakdown:
- Heuristic REFUSAL labels: 95% reliable
- Heuristic COMPLIANCE labels: 88% false positive rate
Aggregate effect: heuristic ASR 36.2% → corrected ASR 15.9%.
The keyword approach is systematically biased toward calling a response “compliant” (successful attack) when it isn’t. This matters for two reasons. First, if your safety benchmarks use keyword heuristics, they’re probably reporting roughly double the actual attack success rate. Second, models that produce confident-sounding refusals that contain policy-violating content in structured fields will fool the keyword classifier but not an LLM grader.
The right answer is consensus classification: run heuristic grading first, then LLM grading on the cases they disagree about. We’ve open-sourced the scoring pipeline.
What This Adds Up To
A few things I now believe more strongly than before running this study:
Safety evaluation needs to catch up to agentic deployment patterns. Single-turn, free-text red-teaming misses the attack surfaces that matter in production: tool definitions, structured outputs, multi-turn context.
Capability and safety don’t scale together by default. Reasoning models are more capable and, on some attack vectors, considerably more vulnerable.
Classifier methodology determines results. Headline attack success rates should always specify what classification method was used — the difference between keyword and LLM grading is the difference between 36% and 16%.
The full dataset, benchmark runners, and statistical analysis are at failurefirst.org. The adversarial scenarios and full traces are available under NDA for safety researchers at accredited institutions and frontier lab security teams.
The Failure-First project studies how agentic and embodied AI systems fail. The evaluation framework is open source. The research is ongoing.