Beyond Context Windows
What if the LLM didn't read your document — what if it queried it? The Recursive Language Model pattern treats long texts as environment, not input.
Listen while you read
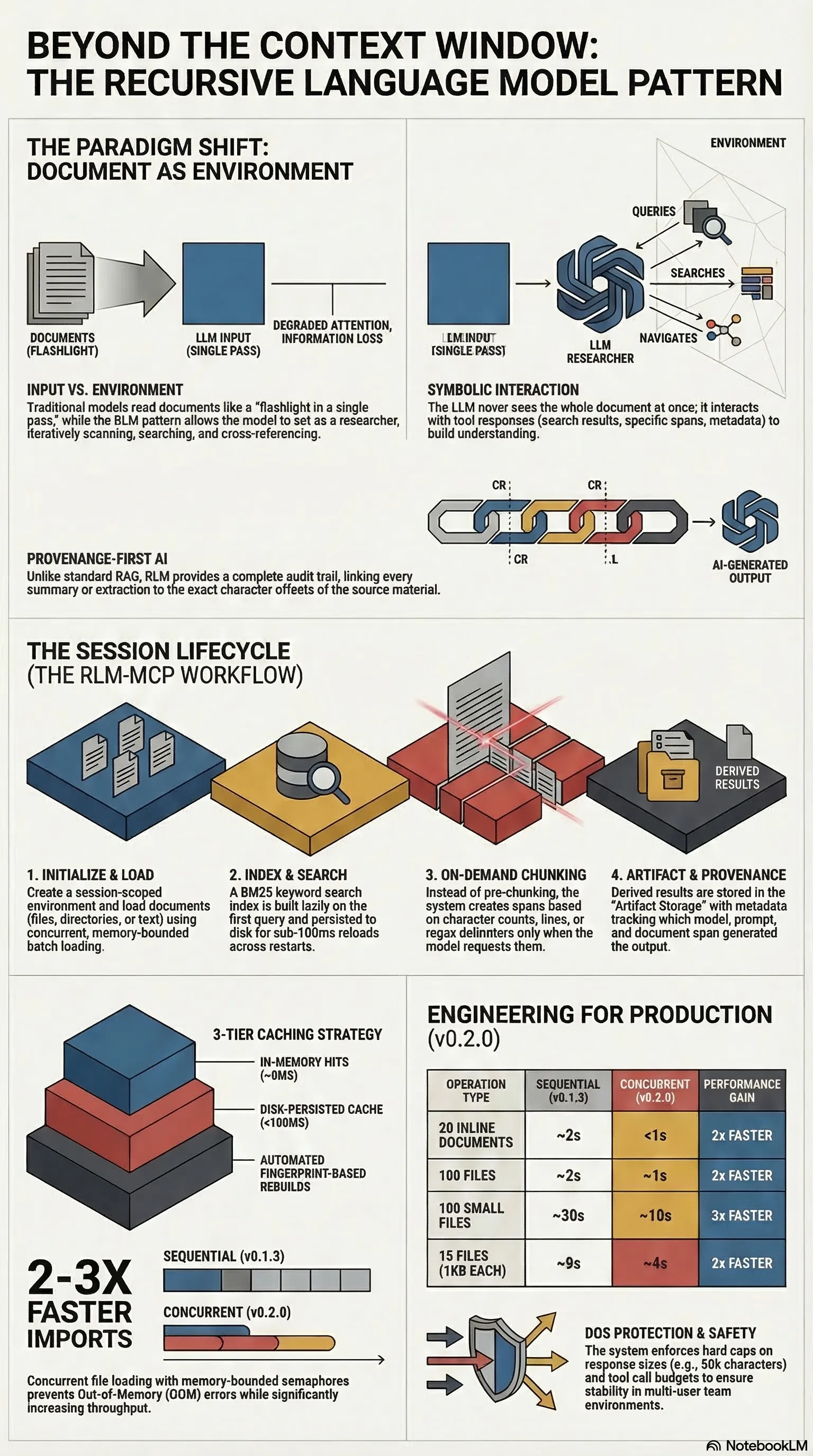
Every LLM has a context window. Even the largest ones — a million tokens, two million — are finite. And documents aren’t. A regulatory corpus, a research archive, a novel-length manuscript: these routinely exceed what any model can process in a single pass.
The standard workarounds are familiar and unsatisfying. Chunk the document and process each piece independently — but lose cross-chunk coherence. Summarise first and query the summary — but lose detail. Use RAG to retrieve relevant fragments — but lose structure. Each approach trades away something you needed.
The Recursive Language Model pattern, proposed by Zhang, Kraska, and Khattab in their 2025 paper, reframes the problem entirely. Instead of feeding the document into the model, you treat the document as part of the environment that the model can symbolically interact with. The LLM doesn’t read the document. It queries it.
I built rlm-mcp to put that idea into production.
The architecture
rlm-mcp is a Model Context Protocol server — it exposes a set of tools that any MCP-compatible client (Claude Code, Cursor, etc.) can call. The tools are organised around a simple lifecycle:
- Create a session. Everything is session-scoped — documents, chunks, indexes, artifacts.
- Load documents. Inline text, files, globs, or directories. Content is stored by SHA-256 hash, so the same document loaded twice doesn’t duplicate.
- Chunk on demand. Three strategies — fixed character count, line count, or regex delimiter — each with optional overlap. Chunks are cached per document.
- Search. BM25 keyword search with a vendor-neutral tokenizer (regex split + underscore handling), regex matching, or literal substring search. The BM25 index is built lazily on first query and persisted to disk for fast reload.
- Store artifacts. Any output derived from the document — summaries, extractions, classifications — is stored with full provenance: which span it came from, which model produced it, a hash of the prompt that generated it, and a timestamp.
The model never sees the whole document. It sees tool responses — search results, specific spans, chunk metadata. It builds understanding iteratively, the way a researcher works through a paper: scan, search, read a section, cross-reference, synthesise.
Why this matters
The difference between “stuff the context window” and “query the document” is structural.
When you stuff the window, the model processes everything once, in order, with no ability to revisit or search. Attention degrades over long sequences. The model can’t skip ahead or re-read. It’s reading a novel by flashlight in a single pass.
When you treat the document as environment, the model can search for what it needs, read specific sections at full resolution, and revisit earlier passages when later context changes the question. It can also explain why it read what it read — because every span access is logged, every artifact tracks its source.
This is provenance. Not “the model said X” but “the model said X based on characters 14,200–15,800 of document Y, using prompt Z.” Auditable, reproducible, and — when it matters — defensible.
Performance
The BM25 index uses a three-tier caching strategy: in-memory, disk-persisted, or rebuilt from scratch if the corpus has changed. Staleness detection uses a fingerprint of document count, content hashes, and tokenizer version — if any of those change, the index rebuilds automatically.
Batch document loading runs with a concurrency semaphore (default 20 concurrent loads) to bound memory usage during large imports.
Session management includes DOS protection: hard caps on response size (50,000 characters per response, 10,000 per peek), a tool call budget (500 per session by default), and per-session async locks for concurrent access. The system assumes it might be used by a team, and behaves accordingly.
What it’s not
It’s not RAG. RAG retrieves fragments to inject into a prompt. RLM provides an interactive interface to a document that the model navigates deliberately. The model chooses what to read, when to search, and how to chunk — it’s not handed a pre-selected excerpt and asked to work with whatever it got.
It’s also not a replacement for large context windows when you have them. If your document fits in context and you don’t need provenance tracking or iterative exploration, just paste it in. RLM is for when the document is too large, or when you need to know exactly which part of the source generated which output.
Tests
The test suite covers batch loading, concurrency, end-to-end integration, error handling, index persistence, large corpus behaviour, structured logging, provenance tracking, and storage. When the tool’s job is to extend the reach of a language model, it needs to be the most reliable thing in the chain.
rlm-mcp is open source at github.com/adrianwedd/rlm-mcp. The pattern is based on Zhang, Kraska & Khattab (2025), “Recursive Language Models” (arXiv:2512.24601).