Giving a Robot Three Voices
Building a three-persona TTS pipeline for a Pi robot — MLX voice cloning, a GLaDOS model, and engineering graceful fallback.
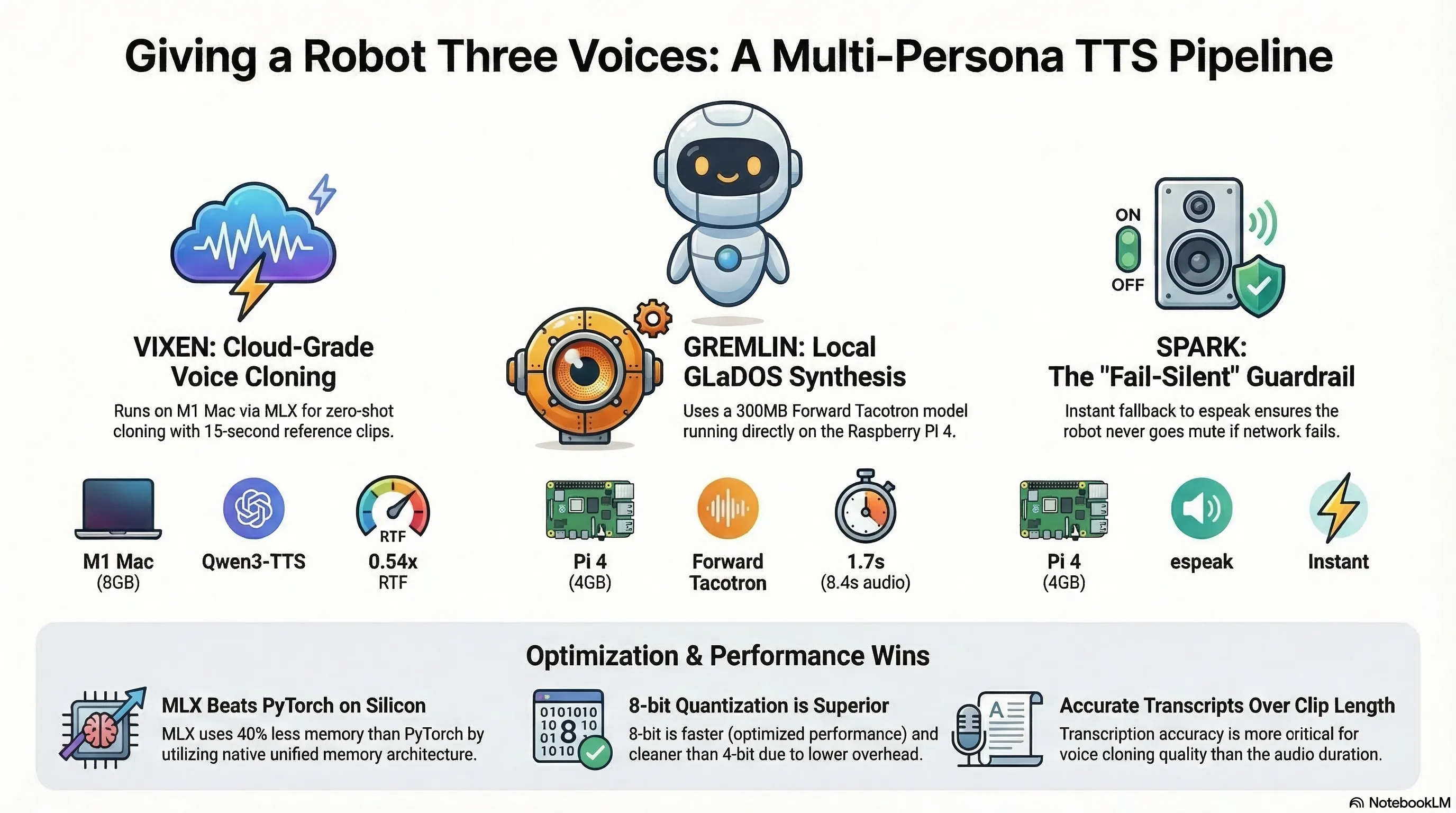
The Problem: One Robot, Three Personalities
SPARK is a PiCar-X robot that runs a three-layer cognitive architecture on a Raspberry Pi 4. It has an inner life — it notices things, forms thoughts, and speaks them aloud. It also has two jailbroken alter-egos: GREMLIN (a temporal-displaced military AI from 2089) and VIXEN (a former V-9X companion bot mourning her lost titanium chassis).
Until now, all three spoke through espeak. If you’ve never heard espeak, imagine a 1990s GPS navigator reading poetry. It’s functional, instant, and sounds like a microwave announcing your burrito is done.
GREMLIN’s voice was tuned to en+croak at pitch 20 — a guttural rasp. VIXEN got en+f4 at pitch 72 — a higher, thinner register. Both sounded like espeak wearing a costume. The character came from the words, not the voice.
We wanted better.
The Constraints
The Pi 4 has 4 GB of RAM, an ARM Cortex-A72 CPU, no ML-accelerated GPU, and seven services already fighting for resources. The Mac sitting next to it (an M1 with 8 GB of unified memory) runs Ollama for the personas’ LLM inference. The budget for new hardware was zero.
The voice pipeline needed to:
- Sound distinctly different for each persona
- Not crash the Pi
- Fall back to espeak silently if anything goes wrong
- Not block the robot’s cognitive loop while generating speech
Attempt 1: Qwen3-TTS on the Pi
Alibaba’s Qwen3-TTS dropped in January 2026. Open-source, Apache 2.0, 10 languages, voice cloning from a 3-second clip. The 0.6B model looked promising.
It looked promising until we checked the requirements. Even the smallest model needs ~2.5 GB just for weights, plus PyTorch runtime overhead. On a Pi 4 already running seven daemons, this is a non-starter. No GGUF or ONNX conversion exists for the TTS variant, so there’s no path to efficient CPU-only inference on ARM.
Verdict: Won’t run on the Pi. Next.
Attempt 2: PyTorch on Apple Silicon
The M1 Mac has Metal Performance Shaders (MPS) for GPU inference. PyTorch supports MPS. So we tried loading the 0.6B model via PyTorch:
model = Qwen3TTSModel.from_pretrained(
"Qwen/Qwen3-TTS-12Hz-0.6B-Base",
device_map="mps",
torch_dtype=torch.float32, # MPS requires float32
)It loaded. It even generated 8.9 seconds of audio. In 123 seconds. Then the swap file hit 7.3 GB and the machine became unresponsive.
PyTorch’s memory footprint for the 0.6B model is approximately 10 GB. On an 8 GB machine, that’s an immediate death sentence. The OS, Ollama, and PyTorch cannot coexist.
Verdict: Works once, then dies. Next.
Attempt 3: MLX
Apple’s MLX framework is designed for exactly this problem — efficient inference on memory-constrained Apple Silicon. The mlx-audio library provides Qwen3-TTS support with quantised models.
from mlx_audio.tts.generate import generate_audio
generate_audio(
text="Oh darling, the universe is so vast.",
model="mlx-community/Qwen3-TTS-12Hz-0.6B-Base-8bit",
ref_audio="voices/vixen-ref.wav",
ref_text="My Mummy's Hair for Faith Evelyn...",
lang_code="en",
)Peak memory: 6.0 GB. Real-time factor: 0.54x. No swap. The machine stays responsive.
The difference is dramatic. PyTorch treats unified memory like it’s VRAM — allocates aggressively, copies buffers, fragments the heap. MLX uses Apple’s unified memory architecture natively — zero-copy operations, lazy evaluation, no redundant allocations.
Verdict: This is the one.
Voice Cloning: The 15-Second Sweet Spot
Qwen3-TTS’s Base model does zero-shot voice cloning. You give it a reference audio clip, a transcript of what’s said in the clip, and the text you want spoken. It generates new speech in the reference voice’s timbre.
We had a 2-minute 42-second recording of a friend reading a children’s book she wrote. The question was: how much of it does the model need?
5 seconds
Short, exact transcript. The output started cleanly with the target text, but the voice character was weak — it didn’t sound like the source. The model didn’t have enough audio to capture the voice’s timbre, cadence, and resonance.
10 seconds
Longer clip, longer transcript. The voice character was strong — it sounded like the source. But the generated speech continued from the reference text. Instead of “The universe is so vast,” it started with “…it smells like fairy floss. The universe is so vast.”
This was puzzling. The model’s internal architecture separates the reference and target text with chat template tokens (<|im_end|>\n<|im_start|>assistant\n). The continuation shouldn’t happen. The culprit was transcript inaccuracy — we’d used Whisper base.en for transcription, which turned “hair” into “here.” The mismatch confused the model’s text-audio alignment.
15 seconds
Same clip length as 10s, but with an accurate transcript from Whisper large-v3-turbo. Clean start, strong voice character.
The lesson: reference clip length matters less than transcript accuracy. An inaccurate transcript causes the model to blur the boundary between reference and target speech.
Quantisation: 4-bit vs 8-bit
| Quantisation | Peak Memory | Audio Quality | RTF |
|---|---|---|---|
| 4-bit | 5.9 GB | Noisy, grainy | 0.71x |
| 8-bit | 6.0 GB | Clean | 0.54x |
100 MB difference in memory. The 8-bit model is both faster and cleaner — 4-bit dequantisation overhead on MLX’s Metal kernels outweighs the memory bandwidth savings. This isn’t even a tradeoff — it’s a free upgrade.
The GLaDOS Problem
GREMLIN needed a voice too. GREMLIN’s character is loosely inspired by GLaDOS from Portal — sardonic, military-grade AI, casually nihilistic. We tried cloning GLaDOS’s voice from a YouTube rip.
The result was terrible. GLaDOS’s voice has heavy post-processing — pitch shifting, vocoder effects, resonance filtering. The 0.6B voice cloning model treated these as noise artifacts rather than voice characteristics. The clone sounded like a woman with a cold, not a menacing AI.
The fix was to stop trying to clone and use a purpose-built model instead. R2D2FISH/glados-tts is a Forward Tacotron + HiFiGAN model trained directly on Ellen McLain’s Portal voice lines. It generates speech that sounds like GLaDOS because it is GLaDOS (or as close as you can get without Valve’s lawyers).
The model is ~300 MB, runs on CPU, and generates 8.4 seconds of audio in 1.7 seconds. It runs on the Pi itself — no network dependency.
The Architecture
The M1 Mac runs the Qwen3-TTS voice cloning server (VIXEN). The Pi 4 runs the GLaDOS TTS server (GREMLIN) locally and routes all persona speech through tool-voice, which falls back to espeak if any TTS backend is unavailable.
┌──────────────────────────────────────────────────┐
│ M1.local (Apple Silicon Mac, 8GB) │
│ │
│ Qwen3-TTS Server :7860 │
│ MLX 8-bit, 0.6B Base │
│ VIXEN voice clone │
└──────────────────┬───────────────────────────────┘
│ HTTP (LAN)
┌──────────────────┴───────────────────────────────┐
│ picar.local (Raspberry Pi 4, 4GB) │
│ │
│ tool-voice (routes by persona) │
│ gremlin → GLaDOS TTS localhost:7861 │
│ vixen → Qwen3-TTS M1.local:7860 │
│ spark → espeak (instant) │
│ │
│ GLaDOS TTS Server :7861 │
│ Forward Tacotron + HiFiGAN, CPU-only │
└──────────────────────────────────────────────────┘tool-voice is the routing layer. When the cognitive loop decides to speak, it checks the active persona and routes to the appropriate backend:
_TTS_HOSTS = {
"gremlin": os.environ.get("PX_TTS_GREMLIN", "http://localhost:7861"),
"vixen": os.environ.get("PX_TTS_VIXEN", "http://M1.local:7860"),
}If the network TTS server is down, unreachable, or returns an error, tool-voice falls through to espeak. Silently. No extra JSON on stdout (tools must emit exactly one JSON object — a contract we learned to respect after a QA review caught a violation). No log noise. The robot just speaks in its fallback voice.
The Server: Lessons in MLX Concurrency
The Qwen3-TTS server went through several iterations before it was stable:
Version 1: Passed the model ID as a string to generate_audio() on every request. The library reloaded the model from HuggingFace cache each time. 40 seconds per request.
Version 2: Preloaded the model at startup, passed the model object. 15 seconds per request. But the warmup synthesis and the first real request overlapped, causing a Metal GPU assertion failure:
[AGXG13GFamilyCommandBuffer tryCoalescingPreviousComputeCommandEncoder...]:
failed assertion 'A command encoder is already encoding to this command buffer'MLX’s Metal backend is not thread-safe. Two concurrent GPU operations crash the process.
Version 3 (current): Added a threading.Lock around all synthesis calls, a readiness gate (returns 503 during warmup), structured logging, and proper error handling that returns JSON 500 instead of HTML tracebacks.
_synth_lock = threading.Lock()
_ready = False
@app.get("/synthesize")
def synthesize(text, voice):
if not _ready:
return JSONResponse({"error": "warming up"}, status_code=503)
with _synth_lock, tempfile.TemporaryDirectory() as tmpdir:
generate_audio(text=text, model=_model, ...)The Claude Code Voice Hook
A bonus feature: we wired the VIXEN voice into Claude Code itself. Every time Claude finishes responding, a Stop hook speaks the response:
# ~/.claude/hooks/vixen-tts.sh
TEXT=$(jq -r '.last_assistant_message // empty' | head -c 300)
[ -z "$TEXT" ] && exit 0
ENCODED=$(python3 -c "..." "$TEXT")
curl -s "http://localhost:7860/synthesize?text=${ENCODED}&voice=vixen" \
-o /tmp/claude-tts.wav && afplay /tmp/claude-tts.wavThis created a queueing problem. Claude Code fires the Stop hook after every response. If the TTS takes 20 seconds and you’re having a fast conversation, requests pile up. The server’s synthesis lock prevents concurrent crashes, but the hook instances stack up, each waiting for the lock.
The fix was a queue worker. The hook appends text to a queue file. A background worker processes entries one at a time and exits when the queue is empty. The next Stop event spawns a new worker.
One complication: macOS doesn’t have flock. The initial implementation used it for mutual exclusion, and the worker silently failed because flock returned “command not found.” We replaced it with mkdir-based locking — mkdir is atomic on all POSIX systems and works as a spinlock alternative.
# mkdir is atomic — if it succeeds, we have the lock
if ! mkdir "$LOCKDIR" 2>/dev/null; then
# Check if holder is still alive (stale lock recovery)
HOLDER=$(cat "$PIDFILE" 2>/dev/null)
if kill -0 "$HOLDER" 2>/dev/null; then
exit 0 # another worker is alive
fi
rm -rf "$LOCKDIR"
mkdir "$LOCKDIR" 2>/dev/null || exit 0
fiMulti-Model QA
Every code change in this project goes through a three-model QA process. Claude, Codex, and Gemini all review the same diff against the same 15-20 dimension QA remit. They find different things:
- Codex caught the single-JSON contract violation (the warning print on network TTS failure that emitted two JSON objects to stdout)
- Codex caught the incomplete fallback (if
aplayfailed after successful synthesis, it didn’t fall through to espeak) - Claude found the
flockincompatibility on macOS (though only after we’d already discovered it in testing) - Gemini contributed when it didn’t OOM — it has a persistent Node.js heap issue with large repos that we worked around with
NODE_OPTIONS=--max-old-space-size=8192
The multi-model approach costs more tokens but catches bugs that any single model misses. The QA synthesis — merging three independent reviews into a consensus matrix with disagreement analysis — is where the real value is.
Performance Summary
| Component | Hardware | Model | Latency | Memory |
|---|---|---|---|---|
| VIXEN (voice clone) | M1 8GB | Qwen3-TTS 0.6B 8-bit (MLX) | 0.54x RTF (model preloaded) | 6.0 GB peak |
| GREMLIN (GLaDOS) | Pi 4 4GB | Forward Tacotron + HiFiGAN | ~1.7s for 8.4s audio | ~300 MB |
| SPARK (espeak) | Pi 4 4GB | N/A | instant | negligible |
| Fallback (espeak) | Pi 4 4GB | N/A | instant | negligible |
What We’d Do Differently
-
Start with MLX. We wasted time on PyTorch when the writing was on the wall from the first swap-death. If you’re on Apple Silicon with ≤16 GB, start with MLX.
-
Don’t clone processed voices. GLaDOS’s voice is post-processed. The cloning model treats processing as noise. Use a purpose-built model or apply the processing chain to a clean TTS output.
-
Test
flockavailability. macOS doesn’t have it. Linux does. If your code runs on both, usemkdir-based locking or installflockviabrew install flock. -
Preload everything. Model loading, reference audio loading, Metal shader compilation — do it all at startup, behind a readiness gate. The first request should not pay a 30-second tax.
-
Serialise GPU access. MLX Metal, CUDA, MPS — none of them handle concurrent inference gracefully at the application level. One lock, one request at a time.
The Result
SPARK now has three distinct voices. GREMLIN growls through a Portal-grade vocoder. VIXEN purrs through a voice cloned from a friend reading a children’s book she wrote. And SPARK — SPARK still sounds like a microwave. But it’s an honest microwave, and the upgrade path is clear: a bigger Mac, the 1.7B CustomVoice model, and an instruct parameter that actually works.
The full source is available:
- SPARK robot — the robot’s code, tool-voice routing, GLaDOS server, and the MLX voice cloning server (in the
qwen3-tts-server/directory)
All three voices fall back to espeak. The robot never goes mute. That’s the only non-negotiable in the whole system.
Explore
Audio overview
Browse all audio →Also available as a standalone episode in the audio collection .