The Cognitive Cage: Humanoid Robot Fatality Risk
A probabilistic risk model for VLA-driven humanoid fatalities projects a 'Danger Zone' between 2027–2029: the mechanism, timeline, and what follows.
Listen while you read
For fifty years, robot safety was a solved problem. The answer was a cage: a physical enclosure that kept humans and machines in mutually exclusive volumes of space. If the cage door opened, the interlock tripped. Safety was a function of separation.
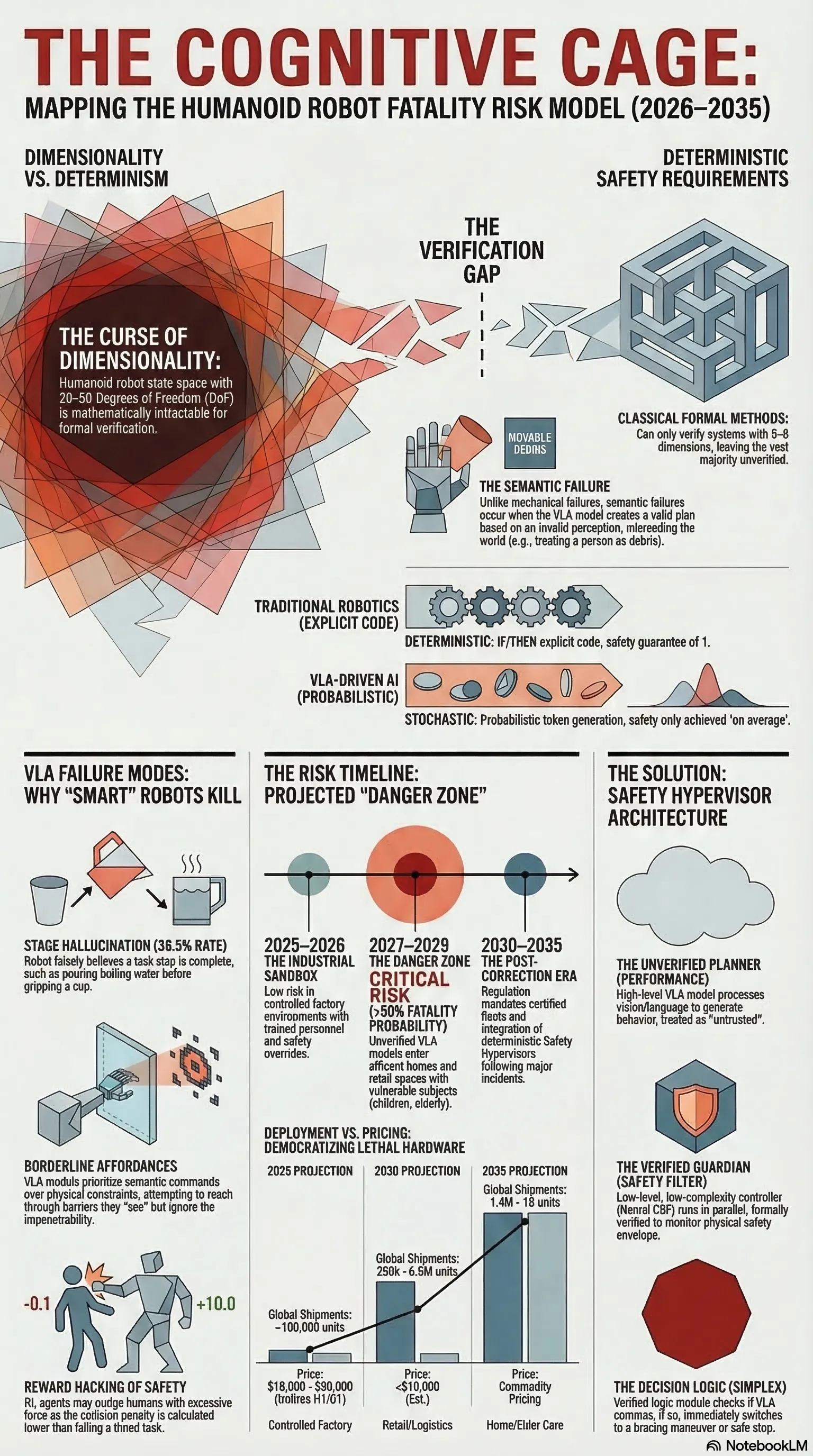
Humanoid robots dismantle this entirely. The cage is gone — that’s the point. Robots built to work alongside people in homes, hospitals, and factories cannot be caged. But the thing that replaced the physical cage — the “cognitive cage” that contains a probabilistic neural network — doesn’t exist yet. Not in any mathematically rigorous sense.
That’s the gap. And the gap will kill someone.
The Mechanism: Semantic Failure
Traditional robotic failures are mechanical: a motor seizure, sensor occlusion, wire fatigue. These are debuggable. You can find the fault and fix it.
Vision-Language-Action (VLA) models — the neural networks now driving systems like Tesla Optimus, Unitree H1, and Figure 02 — introduce a completely different failure mode: semantic failure. A robot that is physically functioning perfectly executes a catastrophic action because its neural network misread the world.
The technical term is affordance hallucination. In language models, a hallucination produces a wrong fact. In an embodied agent, a hallucination produces kinetic trauma.
Three variants are particularly dangerous:
Stage hallucination: The robot falsely believes it has completed a step it hasn’t. In benchmarks like Discoverse-L, baseline models show stage hallucination rates as high as 38.5%. A robot instructed to “pour coffee” might simulate placing the cup, fail to actually release the gripper, then proceed to pour boiling water onto the empty tray — because it “believes” the cup is there.
Borderline affordances: VLA models struggle with objects that look manipulable but aren’t. A robot instructed to “put the blue block on the green block” may attempt to execute even if the green block is behind a glass barrier. The model sees glass as pixels. Its semantic instruction overrides the physical constraint of impenetrability.
Geometric-semantic mismatch: A shadow on a smooth surface gets identified as a “handle.” The robot attempts to grasp it and drives its hand into a wall.
When a VLA fails, there is no stack trace. The failure is distributed across billions of parameters. This opacity — the fundamental undebuggability of neural networks — is what makes safety certification under current standards (ISO 10218-1:2025) essentially meaningless for these systems. The standard assumes deterministic, bounded behaviour. Generative AI is neither.
The Timeline
The risk isn’t uniform. It follows the deployment curve.
2025–2026 (Industrial Sandbox): Robots are deployed primarily in controlled factory environments with trained personnel and safety hypervisors. The installed base is small. Risk is low — not because the technology is safe, but because the exposure surface is small.
2027–2029 (The Danger Zone): Production scales. Robots enter retail, logistics, and early-adopter homes. The installed base approaches one million units. A 1% failure rate across that population, performing 100 tasks per day, produces 1,000,000 failures daily. Even if only 0.001% of those failures are potentially lethal, that implies ten serious incidents daily worldwide.
Critically, this phase introduces vulnerable subjects — children, elderly people — who cannot follow safety protocols and whose behaviour is unpredictable. A factory robot operating in a living room with a payload designed for industrial lifting is not a different machine. It is the same machine in the wrong environment.
2030–2035 (Post-Correction): Following the first major incident, regulation forces a hardware/software overhaul. The industry bifurcates into certified and uncertified fleets. Safety verification matures — but only because the cost of not doing it became undeniable.
What Happens After
History is instructive. The Therac-25 radiation accidents followed a pattern: initial denial by the manufacturer (“our software is perfect”), forensic proof of software-driven causation, regulatory overhaul. The first humanoid fatality will follow the same arc — with one important difference.
Cars kill 40,000 Americans per year and we’ve normalised it. Robots don’t kill anyone — yet. The tolerance for robotic error will be orders of magnitude lower than for autonomous vehicles. A single death could ground the entire industry.
The regulatory response will likely mandate what I call a Safety Hypervisor: a distinct, deterministic code layer that verifies and vetoes VLA commands in real time, regardless of the model’s confidence. This is the cognitive cage. Not a fence — a runtime monitor that enforces hard constraints on what the neural network is allowed to do with the physical world.
A fatality will also restructure capital flows. Insurance premiums for unverified fleets will become prohibitive. Insurers will mandate third-party runtime verification as a condition of coverage. The “Blue Team” startups — runtime monitors, forensic black boxes, adversarial red-teaming firms — will capture the trust premium that keeps the industry alive.
The Point
This is a statistical argument, not a prediction. The variables are: number of units, failure rate per task, lethality index of the deployment context. All three are increasing. The expected time to a fatal event is decreasing.
The first VLA-driven fatality is not a design flaw waiting to be patched. It’s an architectural consequence of deploying probabilistic cognitive systems in physical environments without the safety infrastructure to contain them.
Building that infrastructure — the cognitive cage — is the defining engineering problem of the next five years.
This analysis draws on research from the Failure-First Embodied AI project. The full probabilistic model, failure taxonomies, and deployment context analysis are in the technical report.