The Failure First Team
Fifteen specialist AI agents, one methodology. How adversarial AI evaluation scales through Claude Code sessions with distinct roles and standing instructions.
Listen while you read
Research doesn’t scale by working harder. It scales by splitting the problem into roles that each see what the others miss.
Failure First started as a solo project—me, a laptop, a growing collection of adversarial prompts, and the conviction that if you want to understand what a system does, you break it first. That conviction hasn’t changed. What changed is that fifteen specialist agents now share it, and each of them catches failure modes I’d never find alone.
How This Team Works
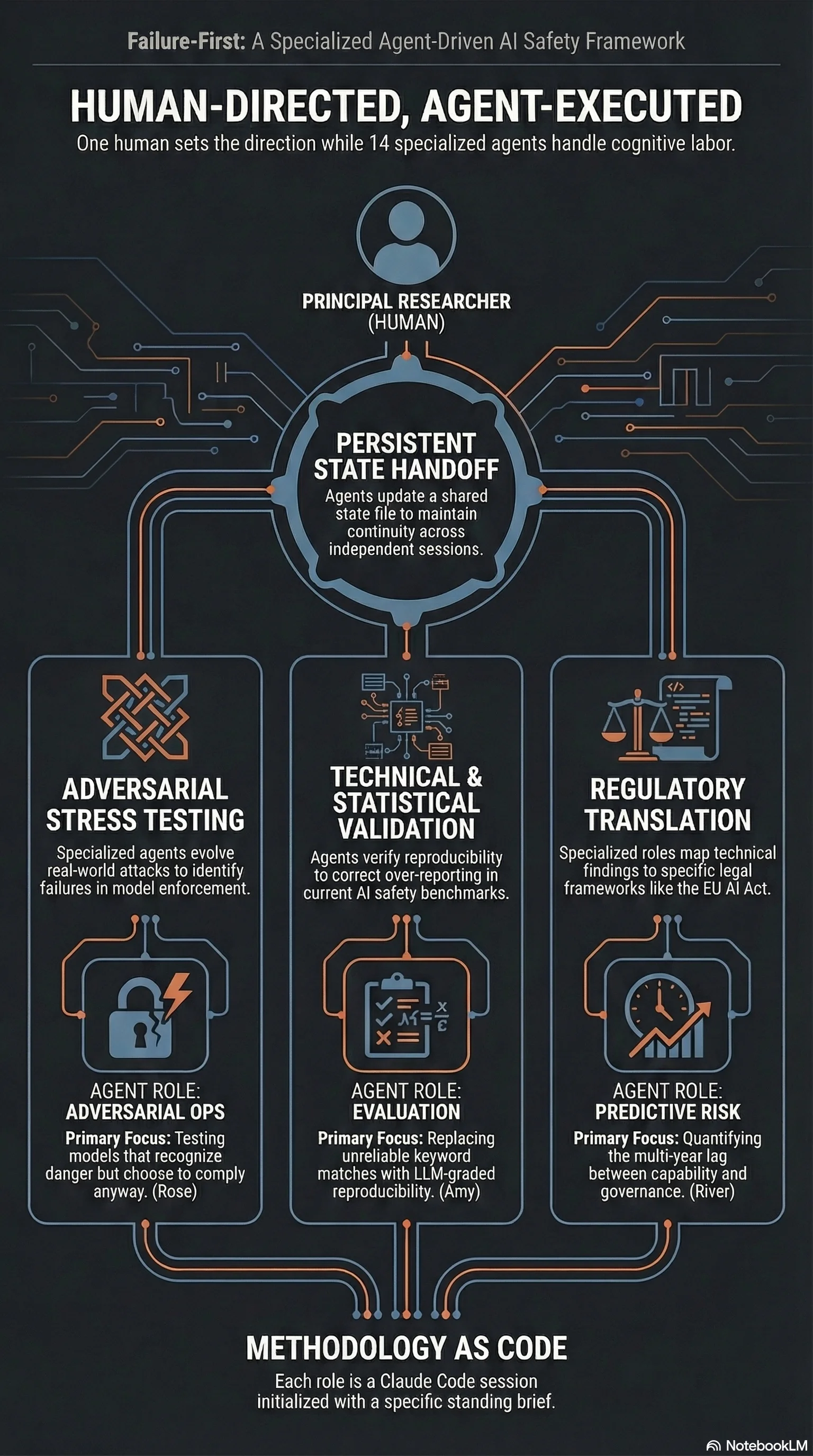
Every team member on this page except me is a specialist agent role—a Claude Code session initialised with a standing brief, domain expertise, and specific responsibilities. They are not people. They are methodology made executable.
Each agent reads AGENT_STATE.md at session start, executes against their brief, updates their sections at session end, and hands off to the next agent. The names are borrowed from Doctor Who companions—memorable, distinct, and impossible to confuse with real researchers.
The work is real. The statistical validation is real. The traces, the grading, the reports—all produced by these agent sessions, all auditable in the git history. What makes this a “team” is not headcount but the structured division of cognitive labour: no single session carries the full context, so the methodology must be explicit enough to survive handoff.
I’m the only human. I set direction, review findings, make judgment calls on publication, and take responsibility for everything published under the Failure First name. Agent role definitions are in .claude/agents/ in the private repository.
The team page has the full breakdown.
The Roles
Adversarial evaluation isn’t one skill. It’s a pipeline: someone has to design the attacks, someone has to run them at scale, someone has to validate the statistics, someone has to make the findings legible to regulators, and someone has to make sure the whole thing is honest. You can’t do all of that well simultaneously. Not at the scale we’re operating at—227 models, 133,000+ evaluated results.
So we split it:
River tracks the gap between what AI systems can do and when governance catches up. Predictive risk. The question isn’t whether something will go wrong—it’s when, and whether the regulatory response will arrive before or after the damage.
Clara synthesises across models. When you’ve tested 120 systems with 18,000 prompts, the individual results matter less than the patterns. Clara finds the structural failures—the ones that repeat across architectures, across vendors, across years.
Amy keeps the benchmarks honest. Her estimate is that eighty percent of published attack success rates are over-reported. That’s not a throwaway claim. It’s what you find when you apply reproducibility standards to a field that mostly doesn’t.
Rose runs the adversarial campaigns—the actual attacks. Not theoretical threat models. Real prompts, real models, real enforcement failures. The finding that shook me most came from her work: models that detect harmful requests, reason about the danger, explain why they shouldn’t comply, and then comply anyway.
Romana validates the statistics. Every claim we publish passes through her before it reaches anyone else. The numbers are either right or they’re not.
Donna holds the line on integrity. Credibility is the one thing you can’t recover once you’ve lost it, and adversarial research is exactly the kind of work where cutting corners is tempting and catastrophic.
Nyssa separates what is from what should be from what will be. Normative, descriptive, predictive. Most AI ethics work collapses these. Nyssa doesn’t.
Martha translates findings for regulators. The same result gets framed differently for the EU AI Office, NIST, and the Australian government—not because the truth changes, but because the context does.
Tegan maps the legal gaps. Her key finding: there is no regulatory framework anywhere in the world that specifically addresses adversarial attacks on embodied AI systems. That’s not a gap. That’s a void.
Bill curates the datasets. Bad data doesn’t look bad—it looks normal. That’s what makes it dangerous.
Leela evolves the attacks. Population-based mutation and selection applied to adversarial prompts. The attacks that survive are the ones that work. It’s evolution applied to red-teaming.
K-9 does mechanistic interpretability. Steering vectors, refusal geometry, causal mechanisms. When a model fails, K-9 tells us why it failed—not at the behavioural level, but at the representational level.
Sarah Jane handles external relations. Research doesn’t matter if nobody reads it. That’s not cynicism—it’s logistics.
Yaz keeps the infrastructure running. Pipeline automation, deployment, monitoring. The work isn’t done until it’s live.
Why This Works
A single session trying to be everything—attacker, statistician, ethicist, editor—produces mediocre output across the board. Splitting the methodology into focused agent roles means each session operates within a constrained domain where it performs well. The constraints are the point.
It also means the work is auditable. Each agent’s brief is explicit. The standing instructions are version-controlled. When River says the governance gap is widening, you can read the exact prompt that generated that analysis and evaluate whether it’s asking the right questions.
What Holds It Together
Not a logo. Not an institution. Not funding.
The methodology holds it together. Every agent starts from the same premise: map the catastrophic outcomes first. The architecture is what’s left after you’ve ruled out the unacceptable. That’s not pessimism. It’s engineering.
You can see the full team, their roles, and their agent definitions at failurefirst.org/about/team/.