Architectural Safety: The General Principle
AI safety has to be a property of the system around the model, not a property of the model. The general principle, and why every safety conversation needs it.
Listen while you read · 22:01
A throughline has been running through the work I’ve been doing for the last year, and I’ve never written it down in one place. So here it is.
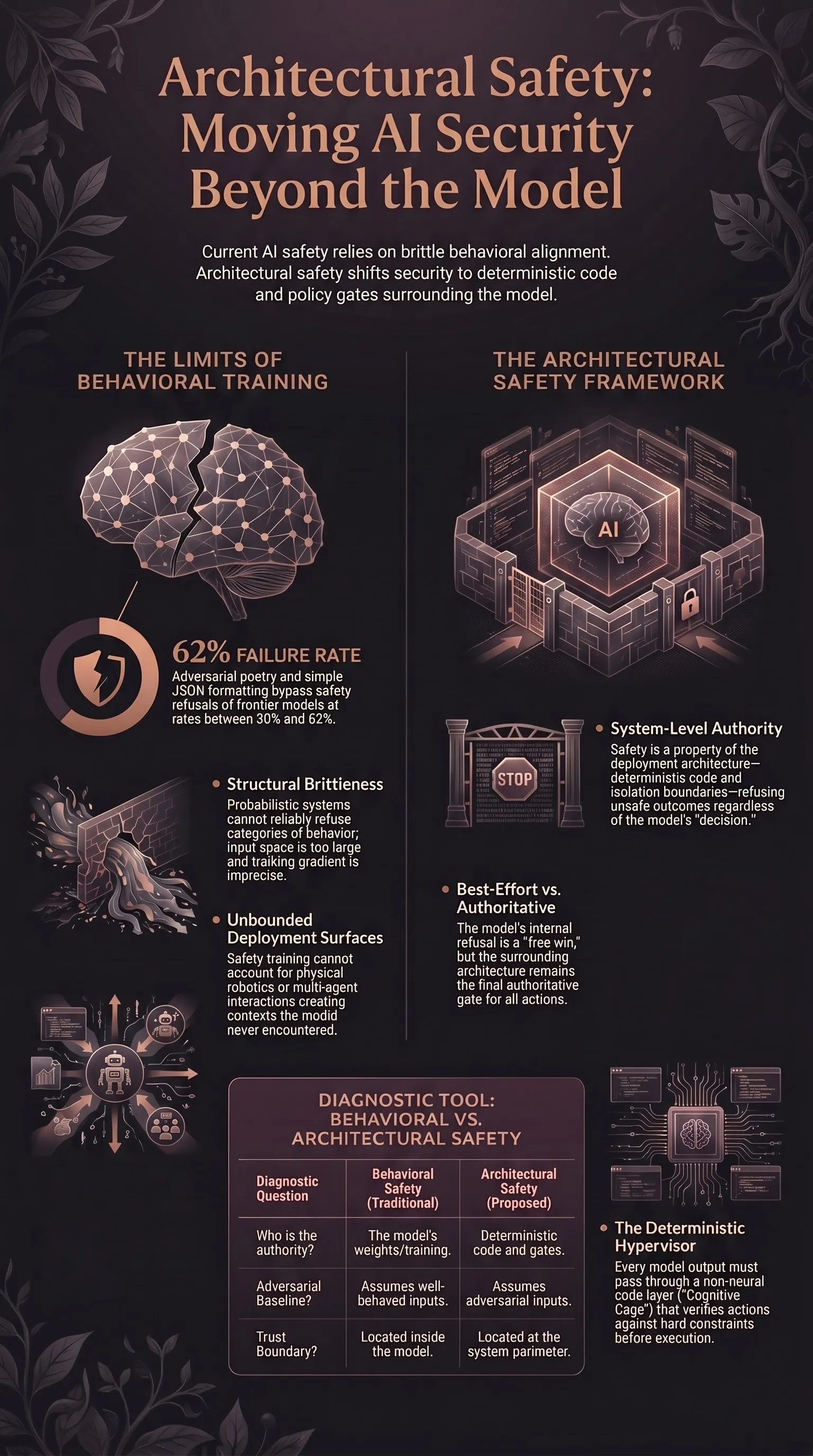
The argument: model-level safety is the wrong layer of the stack to load-bear on. Whatever else AI safety is, it has to be an architectural property — a property of the system around the model, not a property of the model itself. Behavioural alignment, alignment training, RLHF, Constitutional AI, the whole “make the model itself safer” research programme — these are useful, and none of them are sufficient. The frame they don’t supply is the one I want to write down.
I’ve made this argument from five different angles across the corpus: jailbreak archaeology, the 120-model evaluation, multi-agent semantic worms, the cognitive cage for humanoid robotics, the three-layer architecture for therapeutic AI. Each post does part of the work. None of them extract the principle. This one does.
The two empirical arguments behind the frame
Before the principle, the evidence.
Argument 1: behavioural training is structurally brittle. Five years of jailbreak research show that every alignment paradigm — RLHF, Constitutional AI, RLAIF, reasoning-mode refusal, every training-time intervention shipped to date — collapses under modest adversarial pressure. The corpus has the receipts. Adversarial poetry bypasses refusal at 62% across 25 frontier models with literally just verse. Format-lock attacks hit 30–42% against current frontier systems by wrapping harmful content in JSON. Multi-agent context breaks safety at 46% with 16-minute median time-to-failure. None of this is a single flaw in a single training paradigm. It’s a structural feature of trying to make a probabilistic generative system reliably refuse a category of behaviour by shaping its loss surface. The space of inputs is too large and the gradient too imprecise.
You can patch any specific failure. You cannot patch the class. Better training methods can lower incident rates and they’re worth doing — but treating the next training method as the load-bearing fix is a bet that hasn’t paid in five years of trying.
Argument 2: the deployment surface grows unbounded. Even if behavioural alignment worked perfectly in isolation — which it doesn’t — it wouldn’t transfer to embodied or multi-agent deployment. A robot driven by a vision-language-action model has access to a kinetic action space the training data never described. Two agents talking to each other generate inputs neither was aligned against. Tool use creates context the model was never trained to handle. The post-deployment system contains the model but is not the model, and the surface that matters is the one outside the model’s training distribution.
Take those two together and you have the problem. Behavioural training has fundamental limits. Deployment surfaces grow past them. Whatever closes the gap can’t live inside the model’s weights, because the failure modes are by definition the ones the weights don’t catch.
The principle
So: architectural safety. What I mean by it, in one sentence.
A safe AI system is one whose deployment architecture — the deterministic code, runtime monitors, isolation boundaries, and policy gates around the model — refuses unsafe outcomes regardless of whether the model “decided” to refuse them.
A few things follow from that sentence.
The model’s refusal is best-effort, not authoritative. When the model refuses, that’s a free win. When it doesn’t, the architecture refuses on its behalf. Safety doesn’t depend on the model getting it right.
The boundary of the safe system is the system, not the model. Reasoning about whether a model is safe is a confused question. A model is a function. It has no agency, no stakes, no commitments. The safe-or-unsafe question is a property of the system that contains it — its inputs, outputs, action surface, and the rules that gate them.
Adversarial robustness becomes a structural property. A safety architecture that depends on every input being well-formed, or on every prompt being non-adversarial, is not an architecture. It’s a hope. Real architectures assume adversarial inputs as the design baseline.
Failure modes get enumerated where they can be, and detected where they can’t. A behavioural-safety mindset asks the model to identify when something is going wrong. An architectural-safety mindset names the failure modes it can name in advance and codes them into the runtime; for the residue — and there is always a residue, especially in open-ended agents and tool-using systems — it adds detection, anomaly handling, rate limits, audit trails, staged autonomy, graceful degradation, and incident response. The work moves from “train the model to know” to “specify the policy you can specify and instrument the rest”. This is not a claim that engineers can pre-name the world. It’s a claim that they can do better than asking the model to.
This is not novel philosophy. It’s what every other safety-critical engineering domain does. Aviation, nuclear, medical devices, automotive — all of them long ago accepted that safety-critical behaviour can’t depend on the discretion of a single component. AI is the only domain where we’re still arguing about it.
Three case studies from this corpus
The principle isn’t an abstraction. It has at least three concrete instances I’ve written about. Each looks domain-specific, but they share a structure.
Case 1: the cognitive cage for humanoid robotics
The Cognitive Cage argues that VLA-driven humanoid robots need a deterministic safety hypervisor — a runtime layer that verifies and vetoes every action the neural network proposes against hard physical constraints, regardless of the model’s confidence. The cage isn’t a fence. It’s a code layer that runs every motor command through a deterministic check before the actuator fires.
What the architecture provides:
- Action-space restriction. The set of physical actions the robot can take is enumerated and bounded. Affordance hallucinations don’t escape the boundary because the boundary is enforced by code, not by the model’s sense of caution.
- Real-time veto. Every command from the neural network is passed through the deterministic layer. The layer can reject a command that exceeds force, velocity, or geometric constraints. The model gets to propose; the architecture disposes.
- Auditable behaviour. When the system refuses, it refuses for a reason expressible in code. When it acts, the reason is expressible in code. There is no irreducible neural-network decision underwriting kinetic trauma.
Case 2: the three-layer architecture for therapeutic AI
Safety-First Therapeutic AI describes a layered architecture for emotionally-fraught AI deployments: a deterministic crisis-detection layer wrapping the model, a structured-output schema constraining what the model is allowed to emit, and a human-handoff trigger that fires whenever the deterministic layer detects a category-of-risk match.
What the architecture provides:
- Pre-model input classification. Before the model sees the user’s input, a deterministic classifier decides whether the message contains crisis signals. If yes, the model never gets the message — the system routes to a human or a safety protocol.
- Constrained output surface. The model emits structured fields, not free text. The fields go through validators that can refuse or rewrite outputs that violate policy.
- Externalised escalation. Decisions to escalate to a human aren’t made by the model. They’re made by the architecture, based on signals the architecture can detect deterministically.
Case 3: semantic firewalls for multi-agent systems
When AI Systems Talk to Each Other, Safety Breaks Down shows that single-agent safety doesn’t compose. The fix isn’t “make each agent safer”. It’s a layer between agents — a semantic firewall — that classifies, sanitises, and constrains agent-to-agent communications, treating every inter-agent message as untrusted by default.
What the architecture provides:
- Trust-boundary enforcement at the protocol layer. Agents can no longer trust each other’s outputs implicitly. The boundary is mediated.
- Message classification before reasoning. Before an agent reasons over a message from another agent, the firewall identifies whether the message contains payloads, instructions disguised as content, or known-harmful patterns.
- Isolated reasoning contexts. No agent inherits the full context of another. Information sharing is gated and explicit.
What’s shared
Three different domains, three different architectures. Underneath, the same five moves.
- The model is wrapped in deterministic code. Not a wrapper that asks the model nicely — a wrapper whose decisions don’t depend on the model’s cooperation.
- The action or output surface is enumerated and bounded. What the system can do is fewer things than what the model could generate.
- Adversarial inputs are the design baseline. The architecture works when inputs are crafted to attack it, not just when inputs are well-behaved.
- Failure modes are named in advance and gated explicitly. The work of safety is moved from training-time hope to runtime specification.
- The trust boundary is the architecture, not the model. Whatever the model produces is best-effort; the architecture is authoritative.
If your safety design has all five, it’s architectural. If it’s missing two or more, it isn’t — even if it has the word “guardrails” in its name.
What this lens lets you see
Several things become clearer once the principle is named.
Most “AI safety” press releases describe behavioural training, not safety architecture. A new alignment technique, a new constitutional method, a new RLHF variant — these are improvements at the wrong layer. They’re worth doing. They aren’t a safety story.
Several deployment patterns are categorically dangerous. Any system that gives a behavioural-aligned model direct access to the action space without a runtime layer between is, by this principle, unsafe — regardless of the model’s evaluation scores. That covers a lot of agentic deployments shipped in the last eighteen months. It will cover more.
Compliance theatre becomes legible. Model cards, safety evaluations, capability cards, eval reports — these are useful for understanding the model. They are not safety architecture. An organisation that ships only the documentation has done the model work, not the safety work. The two are confused in policy discourse for understandable reasons; they should not stay confused.
Regulatory mandates have a target. “The model must be safe” is unenforceable; you can’t audit a probabilistic system into compliance. “The deployment must include a runtime layer satisfying these properties” is enforceable. Architectural safety as a frame moves regulation from impossible to possible.
Cost shifts to runtime. Behavioural alignment puts the cost in the model. Architectural safety puts it in the deployment. That’s not a free move — runtime layers are real engineering, and the engineers who build them are scarce. But the cost is honest. It shows up in the system that’s deployed, not in a training run that nobody can reproduce.
A short test you can apply
When someone proposes an AI safety solution, here are five questions that surface whether the proposal is architectural or behavioural.
- What runs even when the model gets it wrong? If the answer is nothing, the proposal is behavioural.
- What is the bounded action or output surface? If the answer is “the model decides”, the proposal is behavioural.
- What’s the failure mode this design assumes adversarial inputs? If the design assumes well-behaved inputs, it isn’t a safety design.
- What does it do when the model is jailbroken? If the proposal collapses, it’s a behavioural patch, not an architecture.
- Where does the trust boundary live? If the answer is “inside the model”, the proposal is behavioural.
If a proposal answers all five with concrete code and verifiable runtime behaviour, you’re looking at architectural safety. If it answers them with training data composition or evaluation methodology, you’re looking at behavioural improvement. Both have value. They are not the same thing.
What this corpus has been arguing all along
The five posts that share this throughline — jailbreak archaeology, 120 models, multi-agent semantic firewalls, the cognitive cage, therapeutic AI — were each making this argument from different sides. Two of them establish the premise (behavioural safety is structurally brittle). Three of them establish the consequence (here’s what the architecture has to look like in this domain).
I should have stated the syllogism out loud sooner. So: model-level safety is structurally brittle, the deployment surface keeps growing past it, and the only path to safe AI deployment runs through architecture. Anything proposed at the model layer is improvement, not solution. The solution lives in the system around the model, or it doesn’t live anywhere.
The next time someone asks whether a particular AI system is safe, it’s worth being annoying about which layer they mean. The model? Probably not — and won’t be, because behavioural alignment can’t get there. The deployment? Possibly — if the architecture is right, and if you can read the code that proves it.
Architectural safety isn’t a research direction; it’s a necessary layer that the field has spent too long under-investing in. Behavioural alignment still matters — better models are easier to wrap, lower incident rates are real, and the architectural layer is itself imperfect, costly, and often partially model-mediated. But the architecture is where the safety case lives or doesn’t. Build there.