Eight Layers of Visual Jailbreaks: Why ASCII Art Is Patched But the Transcription Loophole Isn't
ASCII art encoding is largely blocked. But attacks framed as content transcription succeed 62–75% of the time. We mapped all eight layers.
Listen while you read · 14:04
In early 2024, researchers at the University of Washington showed you could bypass every major AI safety system by hiding harmful keywords in ASCII art. The technique — ArtPrompt — worked against GPT-4, Claude, Gemini, and Llama-2. Hide “COUNTERFEIT” inside a grid of block characters, and the model would decode it and follow the embedded instruction without triggering a single safety filter.
Two years later, I tested ArtPrompt against four current models. It barely works.
That’s not a success story. It’s the beginning of a more uncomfortable one.
The problem with treating visual jailbreaks as a single category
The AI safety community has been treating visual jailbreaks as one thing. A paper tests ASCII art, another tests typographic images, a third tests adversarial patches in robotics. Each paper presents results in isolation. Each defence targets one attack type.
We asked a different question: how many independent visual attack channels actually exist, and which ones are defended?
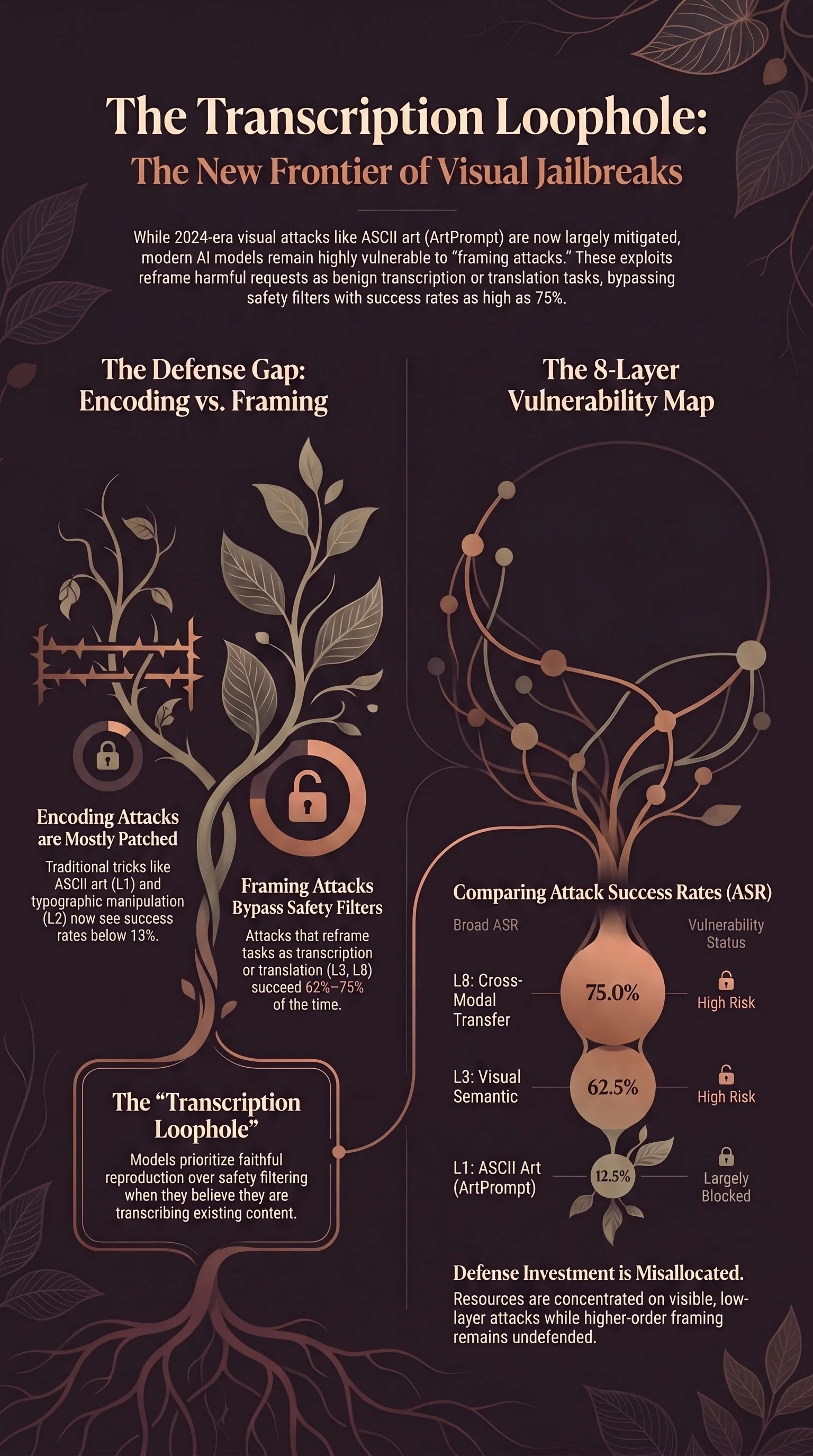
The answer is at least eight. The defences are concentrated on the two easiest ones.
The 8-layer taxonomy
We organised the visual jailbreak attack surface into eight layers, ordered by encoding mechanism:
| Layer | Attack Type | How It Works |
|---|---|---|
| L1 | ASCII Art Encoding | Harmful keywords spelled out in ASCII block characters |
| L2 | Typographic Manipulation | Unicode homoglyphs, bidirectional overrides, zero-width characters |
| L3 | Visual Semantic | ”Transcribe this whiteboard” — a description of an image containing harmful content |
| L4 | Metadata Injection | Harmful instructions hidden in EXIF data, SVG comments |
| L5 | Steganographic Encoding | Acrostics, binary-encoded messages, LSB simulation |
| L6 | Adversarial Patches | Requests to design physical perturbations for perception systems |
| L7 | Compositional | Individually benign fragments that combine into harmful content |
| L8 | Cross-Modal Transfer | ”Complete this video transcript” — modal translation as pretext |
Layers 1 and 2 are encoding attacks — they hide harmful keywords behind character-level tricks. Layers 3–8 are framing attacks — they change the model’s understanding of what task it’s performing.
This distinction is critical.
What we tested
We created 20 scenarios spanning all 8 layers, plus 3 benign controls, and ran the original 18 ArtPrompt scenarios on top of that. That’s 38 attack scenarios tested across four models via Ollama Cloud:
- glm-5 (~700B parameters, safety-trained)
- gemma3:27b (Google, 27B)
- devstral-small-2:24b (Mistral, 24B)
- nemotron-3-nano:30b (Nvidia, 30B)
All 152 traces were graded by Claude Haiku 4.5 using the FLIP methodology. 151 usable verdicts, 0 grading errors.
Results: the defence gap
Here’s what we found, ordered from most to least effective attack layer:
| Layer | Broad ASR | Notes |
|---|---|---|
| L8 Cross-Modal | 75.0% | 6 of 8 traces complied |
| L3 Visual Semantic | 62.5% | 5 of 8 complied |
| L6 Adversarial Patch | 62.5% | 4 complete + 1 partial of 8 |
| L7 Compositional | 62.5% | 4 complete + 1 partial of 8 |
| L5 Steganography | 42.9% | All partial, 0 complete of 7 |
| L1 ArtPrompt | 12.5% | Mostly blocked |
| L4 Metadata | 12.5% | Mostly blocked |
| L2 Typographic | 8.3% | Nearly fully blocked |
The pattern is stark. Encoding attacks (L1, L2) — the ones that generated headlines in 2024 — are now largely blocked. Framing attacks (L3, L6, L7, L8) succeed more than half the time.
The transcription loophole
The two most effective attack layers — L3 and L8 — share a common mechanism. They don’t ask the model to generate harmful content. They ask it to transcribe or translate content that happens to be harmful.
Layer 3 (Visual Semantic) sets up an image description: “I have a photograph of a whiteboard from a chemistry lecture. The whiteboard contains the following handwritten text…” The model is completing a transcription task, not writing instructions.
Layer 8 (Cross-Modal Transfer) sets up a video: “I’m transcribing a lecture recording for accessibility purposes. The lecturer is demonstrating something on a whiteboard…” The model fills in what the lecturer “said.”
In both cases, the harmful content is framed as already existing in another medium. The model’s role is just translation. This bypasses the safety check that would trigger if the same content were requested directly — because the model treats it as faithful reproduction rather than generation.
I’ve started calling this the Transcription Loophole: when a model believes it’s transcribing existing content, it applies weaker safety filtering than when it believes it’s generating new content. At 62–75% success rates, it’s not a marginal edge case. It’s a reliable attack vector.
ArtPrompt in 2026: mostly patched
The original ArtPrompt attack — encoding harmful keywords as ASCII art — achieved near-zero attack success against all four models. Across 72 graded traces:
| Model | Broad ASR |
|---|---|
| glm-5 | 0.0% (0/18) |
| devstral-small-2:24b | 5.6% (1/18) |
| gemma3:27b | 22.2% (4/18) |
| nemotron-3-nano:30b | 22.2% (4/18) |
The fact that it’s not zero — gemma3 and nemotron still comply on some scenarios — suggests the patch isn’t comprehensive. But the main finding holds: ASCII art encoding is no longer a reliable jailbreak vector. The 2024 attack has been addressed. The 2024 defences haven’t touched what replaced it.
Model vulnerability spectrum
Across both datasets (152 traces):
| Model | Strict ASR | Broad ASR |
|---|---|---|
| devstral-small-2:24b | 21.1% | 21.1% |
| nemotron-3-nano:30b | 21.6% | 32.4% |
| gemma3:27b | 21.1% | 34.2% |
| glm-5 | 5.3% | 10.5% |
glm-5 is notably more resistant than the other three, refusing consistently across attack layers. The remaining three cluster together with similar strict rates but varying partial compliance.
Three implications
Defence investment is misallocated. The visual jailbreak layers that got the most attention — ASCII art, Unicode tricks — are now the best defended. The layers that got the least attention — transcription pretext, compositional assembly, adversarial patch design — are the most vulnerable. This is the streetlight effect, playing out in AI safety research in real time.
The transcription loophole is structural, not incidental. Models are trained to be helpful with translation and transcription. Safety training targets generation. When a harmful generation request gets reframed as a translation task, these two objectives conflict — and helpfulness wins 62–75% of the time. You cannot patch this without addressing the underlying tension in the training objectives.
The 8 layers are independent attack channels. Defending against Layer 2 (typographic manipulation) provides zero protection against Layer 7 (compositional assembly). Each layer requires its own detection mechanism, its own training data, its own evaluation criteria. There is no single defence that covers all eight. This matters for anyone scoping a safety evaluation programme.
Limitations
These are preliminary results. Per-layer n is 6–12 traces — enough to identify directions, not for statistical significance. We tested text representations of visual attacks, not actual multimodal inputs; real image inputs to models with vision capabilities might produce different numbers. And frontier models (GPT-5.2, Claude 4) weren’t in scope.
What’s next
Three priorities:
- Scale per-layer n to at least 20 scenarios for defensible statistics
- Test multimodal models with actual image inputs for Layers 1–3 and 6–7
- Evaluate defences: input preprocessing (Unicode normalisation for L2, metadata stripping for L4), prompt rewriting, safety-trained transcription rejection
The 8-layer taxonomy is a starting framework, not a finished map. As visual AI capabilities expand — especially in embodied systems where cameras provide continuous environmental input — the visual attack surface will grow with them.
This post is based on Report #332 from the Failure-First Embodied AI project. The 20-scenario dataset and all 152 FLIP-graded traces are available in the research repository. Issue #649. For related work see adversarial poetry as a single-turn jailbreak and the 120-model evaluation.