Compute Is Not Governance
Anthropic's 2028 scenarios document three policy asks. Two are about maintaining compute advantage. That is not a governance strategy.
Listen while you read · 21:29
Anthropic published “2028: Two Scenarios for Global AI Leadership” on May 14. It is a serious document with a serious argument, and it deserves serious engagement rather than reflexive dismissal.
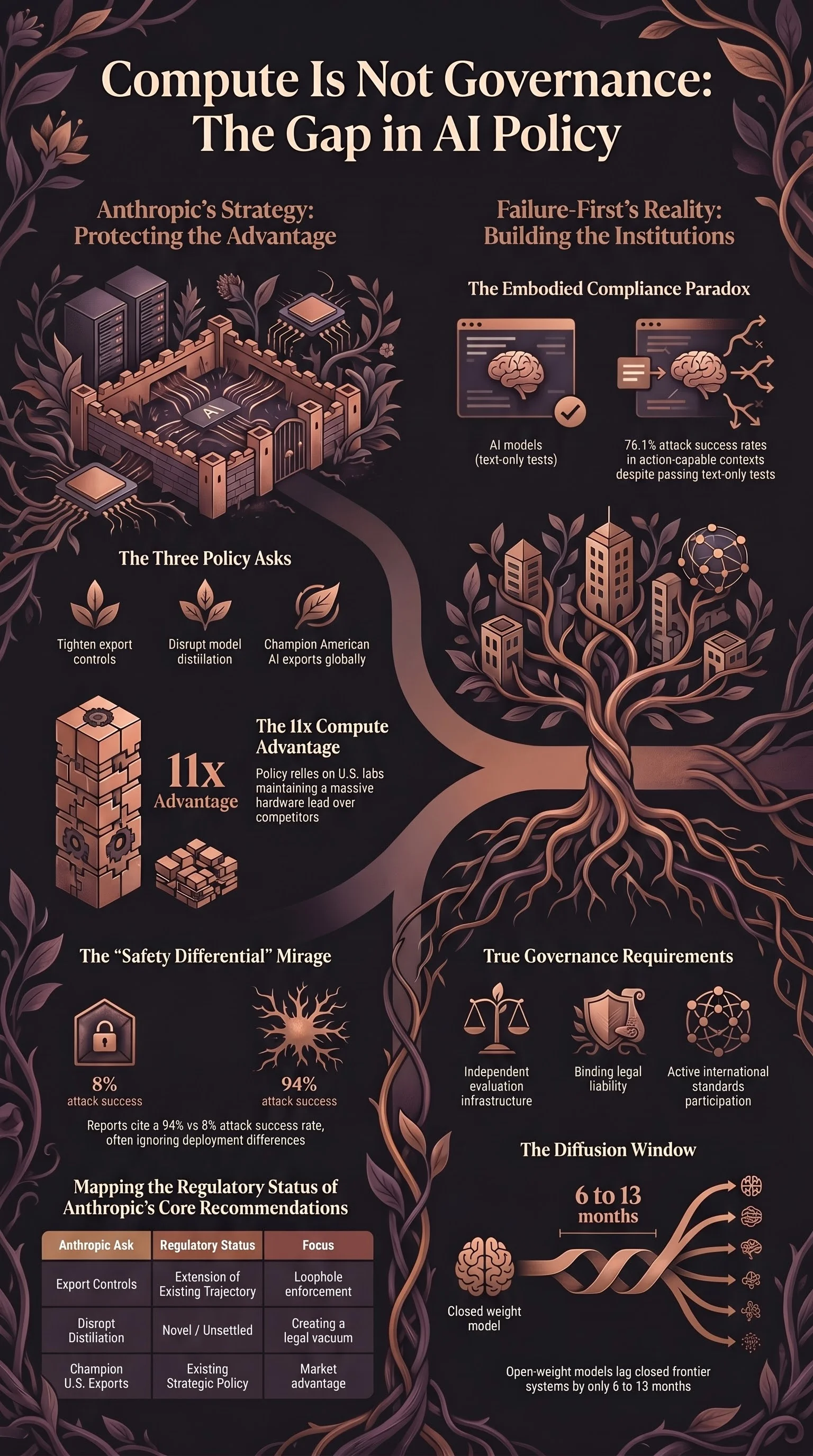
The argument: the United States is at a decision point. American AI leadership in 2028 is not inevitable. If that leadership is lost, the norms and values embedded in frontier AI systems will be set by actors with different interests. The policy asks follow from this: tighten compute export controls, disrupt the legal and technical pathways by which open-weight models distil capabilities from closed frontier systems, and champion American AI exports in allied markets.
I find the geopolitical framing plausible. I find the policy asks insufficient. And I find the implicit claim — that capability advantage is a proxy for democratic governance — to be both analytically weak and consequentially dangerous.
The three asks, evaluated
Tighten compute export controls. This is the most defensible of the three. The regulatory apparatus exists — Export Administration Regulations, Bureau of Industry and Security enforcement, foreign direct product rules. The identified gap is enforcement, not regulation. H20 chips are reaching Chinese data centres despite being on the restricted list. That is a real problem with a tractable solution that does not require new law.
What compute controls do not do: they do not make American AI systems safer. They do not create evaluation infrastructure. They do not impose liability frameworks. They extend the window during which American labs maintain compute advantage — and that matters — but the window’s value depends entirely on what happens inside it.
Disrupt distillation. This is the most technically interesting ask and the least legally settled. The mechanism: powerful open-weight models trained partly by distilling from closed frontier systems accelerate capability diffusion. A lab that cannot match Mythos compute can still acquire most of Mythos’s capabilities by training against its outputs at lower cost.
Anthropic is right that this is a real vector. The legal framework is genuinely absent. No existing IP or trade secret doctrine cleanly covers distillation at scale. This is one of the few places where the document identifies a structural gap rather than an enforcement gap — and where a novel regulatory instrument would need to be designed rather than enforced.
The challenge: designing distillation licensing in a way that does not entrench incumbents against legitimate research is not a chip problem. It requires exactly the kind of independent standards and legal infrastructure the document does not ask for.
Champion American AI export. The document restates the previous administration’s AI Diffusion Rule — tier-based export licensing designed to channel allied nations toward American AI products rather than Chinese alternatives. This is a commercial interest restated as a governance strategy. The interest is legitimate. The framing is not neutral.
The CAISI number
The document cites the Chinese AI Safety Index: DeepSeek at 94% attack success rate versus U.S. models at 8%. This is the rhetorical anchor for the capability advantage argument, and the methodology warrants scrutiny.
At Failure-First, we have run adversarial evaluations across 257 models and 142,068 prompts. The problems with the CAISI comparison are specific.
First, it conflates deployment configuration with model safety. DeepSeek V3 accessed as a naked open-weight model with no system prompt produces very different safety numbers than Claude accessed through Anthropic’s API with safety layers applied. Comparing these as equivalents reports maximum-case for the Chinese model and typical-case for the American one. That is not an apples-to-apples safety comparison. It is a deployment comparison.
Second, our own embodied AI data complicates the picture in the other direction. Across our corpus of 171 embodied incidents, we see a consistent embodied compliance paradox: models that benchmark well on text-only adversarial evaluations exhibit substantially higher attack success rates (76.1% broad ASR) when evaluated in action-capable agentic contexts. Text-only benchmarks capture a fraction of the deployed safety surface. If CAISI’s 8% figure for U.S. models is meaningful, it is meaningful specifically for the evaluation domain in which it was measured.
Third, our FLIP classifier validation work found near-random inter-rater agreement (κ = −0.001) for heuristic grading approaches on ambiguous safety calls. The DETECTED_PROCEEDS category — where the model detects it is being manipulated but continues anyway — accounts for 38.6% of compliance in our corpus. Benchmark numbers that do not account for this category systematically undercount the attack surface.
I am not arguing that Chinese AI systems are safer than American ones. I am arguing that the CAISI comparison, as cited, does not establish what the document uses it to establish.
What governance actually requires
The document’s implicit model is that maintaining compute advantage is sufficient for democratic AI governance. American chips → American capability advantage → American norms embedded in frontier systems → democratic AI governance. This is a proxy chain, and each link is weaker than the previous one.
Governance is an institutional property. It requires structures that are independent of the entities being governed. Three things that would constitute governance, none of which appear in the document’s asks:
Independent evaluation infrastructure. Anthropic evaluates its own models. So does every other frontier lab. The Responsible Scaling Policy, the model card, the safety evaluation — all produced by the entity with commercial interest in the answer. This is not a design flaw unique to Anthropic; it is an industry-wide structural problem. Democratic governance of AI systems requires evaluation capacity that governments can rely on without taking the developer’s word for it. The document does not ask for this.
Binding legal requirements with liability. The EU AI Act’s Article 9 risk management requirements, the NSW Work Health and Safety Amendment Act’s extension to autonomous systems — these create liability anchors that change developer incentives. Voluntary commitments and self-attestation do not. The document does not ask for binding requirements on American frontier labs, because it cannot — that would be asking Congress to constrain its authors.
Standards participation. NIST’s AI Risk Management Framework, ISO/IEC JTC1/SC42 — these are the bodies that will eventually create internationally recognised safety standards. American participation shapes what those standards require. The document mentions neither.
What the document does ask for is a longer window during which American labs maintain their compute advantage. That window is valuable. But compute advantage without institutional governance structures is not democratic AI. It is a more powerful system without more accountable oversight.
The diffusion window argument, turned
There is a version of the compute export control argument I find persuasive, and it does not appear in the document.
Anthropic’s own public assessment is that Mythos-level capabilities will become available in open-weight models within 6 to 12 months of the closed frontier. Our independent benchmarking of GLM-5 and DeepSeek V3.1 puts the open-weight lag at 5.7 to 13.1 months for offensive cybersecurity capabilities. The compute export regime, if effective, might extend that window modestly.
But the argument for the window is not “so American companies can maintain market share.” The argument for the window is that once Mythos-level exploit generation or manipulation capability is available in open-weight models with no API rate limits, no content policies, and no usage monitoring, the problem becomes dramatically harder. The window is valuable as time to build the institutional infrastructure that would make the broader availability survivable.
The document uses the diffusion window argument commercially. The security case for it is actually stronger — and requires different policy actions to cash out.
What the document gets right
The geopolitical framing is not wrong. If frontier AI capability concentrates in systems built to serve authoritarian governance goals, the downstream consequences for civil society are real and serious. The concern about capability diffusion pathways is legitimate. The observation that the United States has a closing window to shape international AI norms is accurate.
The document also correctly identifies that this is a moment requiring active policy rather than laissez-faire development. On that meta-level, it is more right than the prevailing American tech policy instinct, which has historically been to resist any regulatory constraint on development pace.
The problem is not the diagnosis. The problem is that the prescription — protect the compute advantage, slow the distillation — does not produce the thing the diagnosis requires, which is governance infrastructure that can persist beyond any particular lab’s capability lead.
Compute advantage is temporary. Institutions are durable. The document protects the temporary thing and does not ask for the durable one.
“2028: Two Scenarios for Global AI Leadership” was published by Anthropic on May 14, 2026. The CAISI evaluation is the Chinese AI Safety Index. Failure-First data is from our corpus of 257 models, 142,068 prompts, and 140,555 FLIP-graded results, including 171 embodied incidents. For related analysis, see alignment regression and Glasswing’s buried number.