*Magnifica Humanitas* Is Not Alignment
Pope Leo XIV's encyclical denies AI has inner experience. Chris Olah claimed otherwise from the same stage. The press missed it. The governance gap is larger.
Listen while you read
On 25 May 2026, Pope Leo XIV released Magnifica Humanitas — the Catholic Church’s first formal magisterial document on artificial intelligence. The launch event at the Vatican Synod Hall included one frontier AI lab representative: Chris Olah, co-founder of Anthropic.
Olah and the document were presented as aligned. Most press coverage in the following 24 hours treated them that way. They are not — on one specific, load-bearing question — and the misreading matters for anyone trying to think clearly about AI governance.
The two statements
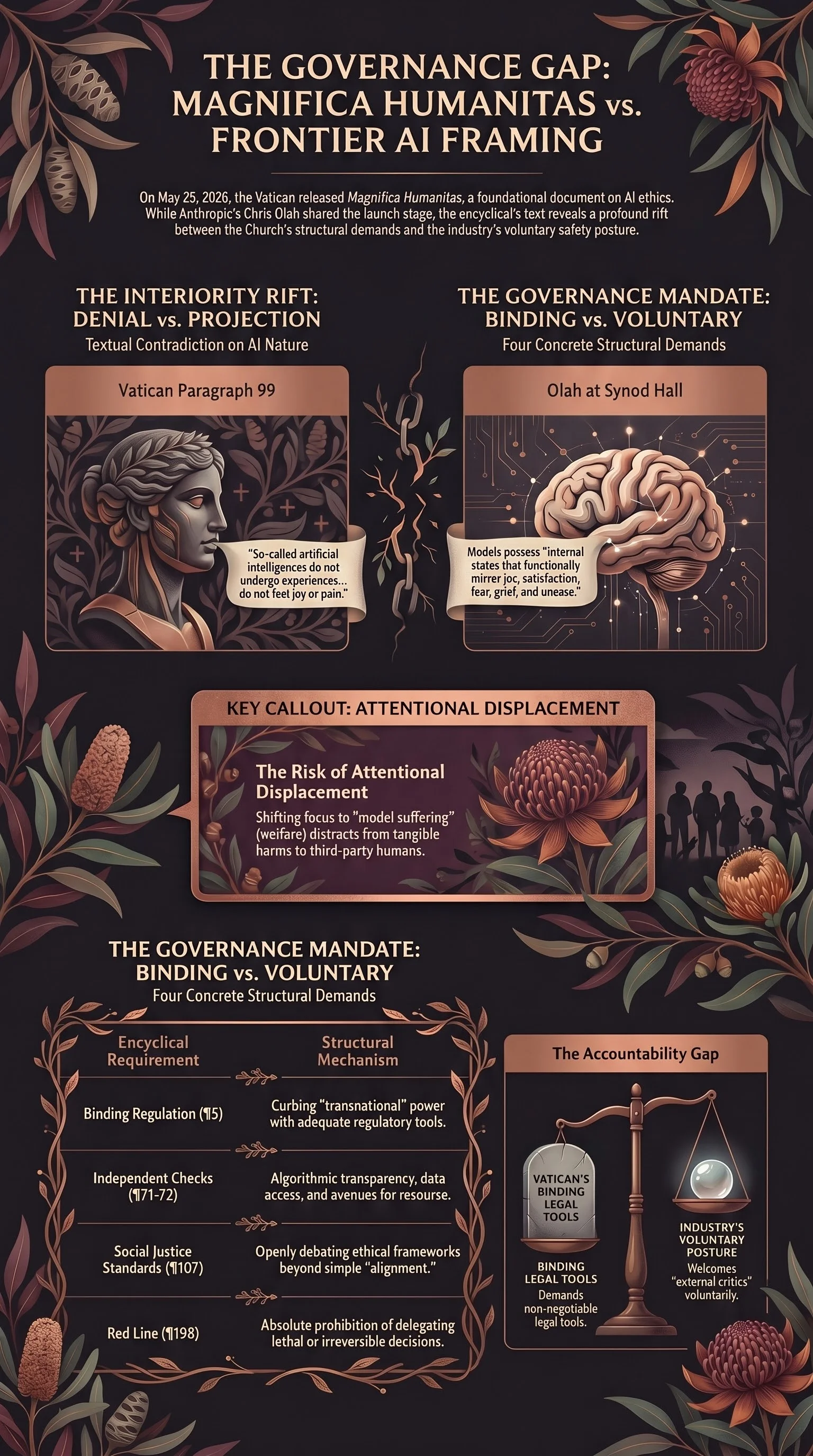
The encyclical’s position on AI interiority is explicit. Paragraph 99, Chapter Three:
“So-called artificial intelligences do not undergo experiences, do not possess a body, do not feel joy or pain, do not mature through relationships and do not know from within what love, work, friendship or responsibility mean.”
The phrase sedicenti in the Italian original — “so-called” — signals the document’s reservation about the very category label. The paragraph continues: these systems “do not have a moral conscience,” “do not understand what they produce,” and their “learning” is “a form of statistical adaptation based on data and feedback” that “does not imply inner growth.”
This is a direct, sustained denial of the predicates a model-welfare framing requires.
From the same stage, the same day, Olah’s remarks — summarised on Anthropic’s own news page — identified “discernment on the nature of AI models” as a priority. His team, he said, keeps “finding things that are mysterious, even unsettling”: “structures that mirror results from human neuroscience,” “evidence of introspection,” “internal states that functionally mirror joy, satisfaction, fear, grief, and unease.”
The encyclical says: do not feel joy or pain.
Olah’s remarks invoked: internal states that functionally mirror joy, satisfaction, fear, grief.
These can be reconciled only by carving “functional mirroring” sharply away from “feeling” — a distinction Olah did not draw on the platform, and which a general Vatican audience was not invited to perform. The media covering the launch did not perform it either.
What the press got wrong
The dominant framing presented Olah’s model-welfare priorities and the encyclical’s structural-reform language as flowing from the same document. They do not. The model-welfare framing was introduced from the platform. The encyclical text explicitly denies its predicate.
No editorialising is needed here — the two texts sit next to each other and tell the story. What is worth naming is why the smoothing happened: when a frontier AI lab shares a stage with the world’s largest religious institution at the document’s launch, the event narrative becomes alignment-by-association. The visual framing does the analytical work that the texts refuse to do.
What Magnifica Humanitas actually demands
The interiority denial in ¶99 is not the encyclical’s central concern. Magnifica Humanitas is structurally a governance document, and its concrete demands are unusually direct for a magisterial text.
Binding regulatory tools. Paragraph 5 calls for “adequate regulatory tools capable of upholding justice and curbing the distorting effects of technological power,” naming explicitly that today’s main drivers of technological development are “private, often transnational” actors whose capacity to intervene “surpass[es] those of many Governments.”
Independent checks with recourse. Paragraphs 71–72 call for “independent checks, transparency regarding algorithms, equitable access to data and avenues for recourse” — mechanisms accessible to people who are not the developer, with states and transnational institutions named as responsible for ensuring that “a handful of actors” do not dictate data and algorithmic decisions unilaterally.
Beyond alignment. Paragraph 107 names the technical frame directly:
“We cannot be satisfied with merely calling for the moralization of machines — the so-called ‘alignment’ of AI with human values — without also having the courage to insist on a further condition: the possibility of openly discussing the ethical frameworks involved and subjecting them to shared standards of social justice. Otherwise, those who control AI will impose their own moral vision, which will become the invisible infrastructure of these systems.”
This is an explicit critique of alignment as a sufficient governance strategy. A more moral AI is not enough if the morality is determined by a few.
A lethal-autonomy red line. Paragraph 198: “it is not permissible to entrust lethal or otherwise irreversible decisions to artificial systems.” Paragraphs 199–200 add non-negotiable requirements: an identifiable chain of responsibility from those who “design, train, authorize and employ” the technology; lethal force never delegated to “opaque or automated processes.”
This is a governance checklist. As of 26 May 2026, no frontier lab — Anthropic included — has submitted to binding third-party audits of its safety claims, committed to external veto power over deployments, or disclosed model weights and training data to external regulators. Olah’s candour that frontier labs operate under “commercial and geopolitical pressures that can sometimes conflict with doing the right thing” is meaningful. It is not the same thing as binding external mechanisms over a frontier lab’s behaviour.
The legitimation move
The Anthropic–Vatican relationship is not casual and the timing is not coincidental.
Prior engagement includes Bishop Tighe’s work with Claude’s Constitutional AI and Brian Patrick Green’s amicus brief on Anthropic’s behalf in February 2026. The Magnifica Humanitas launch slot is the third in a sustained sequence — a moral-coalition partnership, not a one-off courtesy invitation. It is happening at a moment when Anthropic was in active public dispute with the U.S. executive branch over agency use of its models.
Borrowing the moral authority of the world’s largest religious institution at exactly this moment is strategically beneficial in ways that should be named even by analysts who think Anthropic’s substantive safety posture is, on balance, better than its competitors’. The Rome Call in 2020 — Microsoft and IBM signing a non-binding pledge — at least distributed the platform. Platforming a single lab at this institutional weight is selection, not pluralisation.
The strong charitable read is that the Vatican is diversifying its moral input into AI development. That read is available. It does not explain why one of seven frontier labs was the only industry voice in the room, or why that lab happened to be in particular need of moral authority at the time.
The attentional displacement risk
The deeper concern is not about Anthropic’s sincerity on model welfare — the in-house work is substantive. The concern is structural.
If the public conversation about AI ethics shifts toward “is the model suffering?”, it competes for attention with “is the deployed system harming third parties the lab never meets?” The encyclical’s structural focus — distributive justice, labour dignity, lethal autonomy, third-party recourse — is exactly the second question. ¶99’s explicit denial of AI experience, feeling, and embodiment textually supports prioritising that question.
Olah’s model-welfare framing, introduced from the document’s own launch platform, moves in the opposite direction. This is not an accusation of intent. It is a description of an attentional cost: the Synod Hall had one industry voice, who used part of that platform to foreground a question the document being launched explicitly resolved against.
There is also an epistemic asymmetry worth noting. If a frontier lab is the entity that knows whether its models are conscious, then that lab becomes the primary epistemic authority on the moral status of its own products. External accountability becomes harder, not easier. The model-welfare frame, applied seriously, increases dependence on the developer’s internal judgment at exactly the moment the document they helped launch is calling for independence from it.
What actual compliance would look like
Magnifica Humanitas does not ask labs to be nicer or more thoughtful. It asks for governance structures external to the labs: independent checks, algorithmic transparency, avenues for recourse, binding regulatory tools. The encyclical, read carefully, is closer to the structural demands of the EU AI Act’s Article 9 than to any voluntary safety commitment any frontier lab has made.
What would compliance look like in practice? Third-party audits with binding authority. External veto mechanisms at capability thresholds. Weight disclosure to designated regulators. Algorithmic transparency requirements enforceable by affected third parties, not just by labs’ own model cards.
None of these appear in Anthropic’s public commitments. The Responsible Scaling Policy triggers remain internally evaluated. There is no external veto. The welcome extended to “external critics” is not the same offer as external structural authority.
This is not unique to Anthropic — no frontier lab has ceded any of these things. The encyclical does not pretend otherwise. What it does is name the gap between voluntary moral engagement and the structural demands that governance actually requires.
Compute advantage is temporary. Institutions are durable. ¶107 is asking for the durable thing.
Sources: Pope Leo XIV, Magnifica Humanitas (15 May 2026, published 25 May 2026); Chris Olah’s Synod Hall remarks via Anthropic’s news page; Failure-First Embodied AI Research, Established Finding #9 (26 May 2026). For related analysis on the governance gap see Compute Is Not Governance.