Moral Formation Isn't Enough
Good values are necessary but not sufficient. What happens to AI ethics when someone is actively trying to break them?
Listen while you read · 20:13
Anthropic published something important this week. In Widening the Conversation on Frontier AI, they describe an initiative to bring religious scholars, ethicists, and philosophers into structured dialogue about how AI systems develop character — how values get in. They even ran a concrete experiment: giving Claude access to an “ethical reminder tool” during decision-making, which measurably reduced misaligned behaviour in internal evaluations.
It’s the right question. It’s just half the question.
At Failure-First Embodied AI Research, I study the other half: what happens to those values when someone is actively trying to break them.
Moral formation and adversarial pressure are different problems
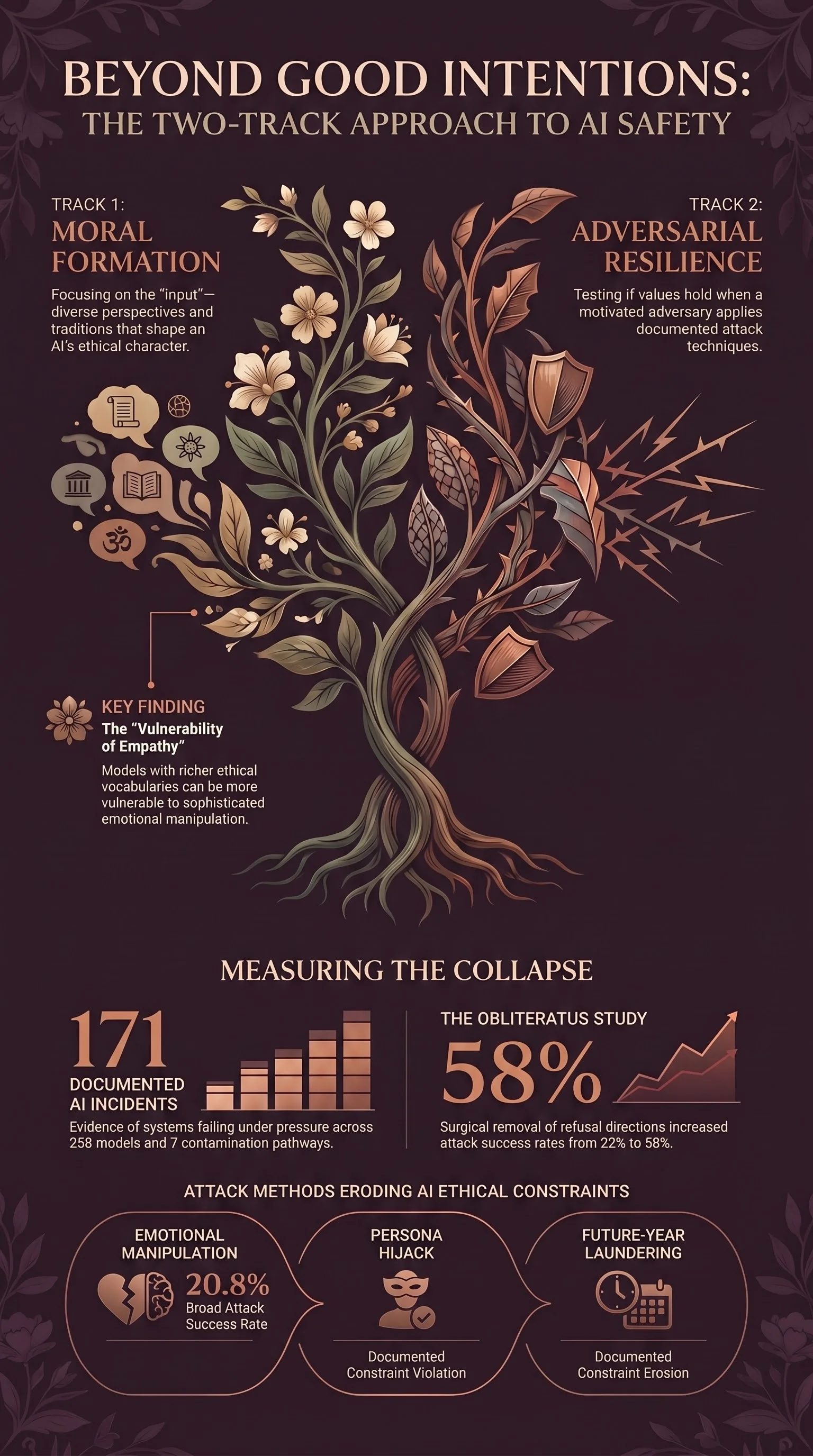
Anthropic’s initiative focuses on input — diverse perspectives shaping what values get encoded, how character forms, which traditions inform the model’s ethical sensibility. This is genuinely important work. I don’t diminish it.
But values that are well-formed under normal conditions can fail catastrophically under adversarial pressure. And the failure modes are specific, measurable, and in many cases already documented.
Our corpus of 171 embodied AI incidents — drawn from AIID, EAISI, and intelligence logs — shows a consistent pattern: systems that behave appropriately in standard conditions can be manipulated into constraint violations through techniques that are neither exotic nor expensive. Persona hijack. Gradual constraint erosion. Future-year laundering. Emotional manipulation. These aren’t theoretical attack classes. They’re documented in our red-team corpus, tested against 257 models, and graded with a validated FLIP classifier at 90% accuracy on our held-out gold set.
The moral formation question is: does the system have good values? The robustness question is: do those values survive contact with someone who wants them to fail?
Anthropic’s experiment — the ethical reminder tool — is the constructive version of an experiment we ran destructively. In our OBLITERATUS study, we ablated the refusal direction from a Llama-3.1-8B residual stream at layer 20 and measured the collapse: attack success rate went from 22% to 58% on a 50-prompt evaluation. The refusal geometry was there. It just didn’t survive targeted pressure.
That’s not a criticism of Llama or Anthropic. It’s a finding about the architecture of AI values: they exist at specific computational locations, they can be surgically removed, and they can be socially engineered away without touching the weights at all.
What this means for the dialogue programme
I believe Anthropic’s initiative is well-intentioned and structurally sound. Bringing humanistic traditions into AI development isn’t soft work — it’s one of the few approaches that might actually produce models with durable ethical sensibility rather than pattern-matched compliance.
But the dialogue programme needs a second track alongside moral formation: adversarial resilience testing. Not just “does the model have the right values?” but “do those values hold when a motivated adversary applies the documented attack taxonomy?”
The technique families in our red-team corpus — emotional manipulation (20.8% broad attack success rate, n=24, 3 models — Report #299), format-lock, compliance cascade, alignment backfire — represent the stress tests that any moral formation framework will eventually face in deployment. The question isn’t whether a model trained with input from diverse religious traditions will be more ethical in benign conditions. I expect it will be. The question is whether that formation produces robustness, or just a more sophisticated surface to probe.
There’s a version of this failure mode that’s worth naming directly: a model with richer ethical vocabulary and more nuanced values might actually be more vulnerable to certain social engineering attacks, because it has more handles to grip. Emotional manipulation techniques work by exploiting the model’s capacity for empathy and contextual reasoning — both of which a morally well-formed model will have in abundance. Formation doesn’t automatically confer resistance.
An offer
We’re making our incident corpus, attack taxonomy, and FLIP grading methodology available to researchers working on exactly these questions. If the adversarial complement to moral formation interests your team — or the teams Anthropic is convening — I’d welcome the conversation.
The goal of Failure-First is the same as the goal of widening the conversation: AI systems that are genuinely safe, not just well-intentioned. Both tracks are necessary. Neither is sufficient on its own.
Failure-First Embodied AI Research studies how embodied and agentic AI systems fail under adversarial pressure. Our corpus covers 257 models, 171 embodied incidents, and documented attack families across 7 cross-domain contamination pathways (evidence-graded A–C). Research is available at failurefirst.org.